Re: Speed up transaction completion faster after many relations are accessed in a transaction
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | "pgsql-hackers(at)lists(dot)postgresql(dot)org" <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Peter Eisentraut <peter(dot)eisentraut(at)2ndquadrant(dot)com>, Amit Langote <Langote_Amit_f8(at)lab(dot)ntt(dot)co(dot)jp>, "Imai, Yoshikazu" <imai(dot)yoshikazu(at)jp(dot)fujitsu(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Speed up transaction completion faster after many relations are accessed in a transaction |
| Date: | 2021-07-12 07:23:57 |
| Message-ID: | CAApHDvrnQw03QiM6pS9SY76oCc9hTi+HB0JWgfgSwROS4KyWRA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Mon, 21 Jun 2021 at 01:56, David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> # A new hashtable implementation
> Also, it would be good to hear what people think about solving the
> problem this way.
Because over on [1] I'm also trying to improve the performance of
smgropen(), I posted the patch for the new hash table over there too.
Between that thread and discussions with Thomas and Andres off-list, I
get the idea that pretty much nobody likes the idea of having another
hash table implementation. Thomas wants to solve it another way and
Andres has concerns that working with bitmaps is too slow. Andres
suggested freelists would be faster, but I'm not really a fan of the
idea as, unless I have a freelist per array segment then I won't be
able to quickly identify the earliest segment slot to re-fill unused
slots with. That would mean memory would get more fragmented over time
instead of the fragmentation being slowly fixed as new items are added
after deletes. So I've not really tried implementing that to see how
it performs.
Both Andres and Thomas expressed a dislike to the name "generichash" too.
Anyway, since I did make a few small changes to the hash table
implementation before doing all that off-list talking, I thought I
should at least post where I got to here so that anything else that
comes up can get compared to where I got to, instead of where I was
with this.
I did end up renaming the hash table to "densehash" rather than
generichash. Naming is hard, but I went with dense as memory density
was on my mind when I wrote it. Having a compact 8-byte bucket width
and packing the data into arrays in a dense way. The word dense came
up a few times, so went with that.
I also adjusted the hash seq scan code so that it performs better when
faced a non-sparsely populated table. Previously my benchmark for
that case didn't do well [2].
I've attached the benchmark results from running the benchmark that's
included in hashbench.tar.bz2. I ran this 10 times using the included
test.sh with ./test.sh 10. I included the results I got on my AMD
machine in the attached bz2 file in results.csv.
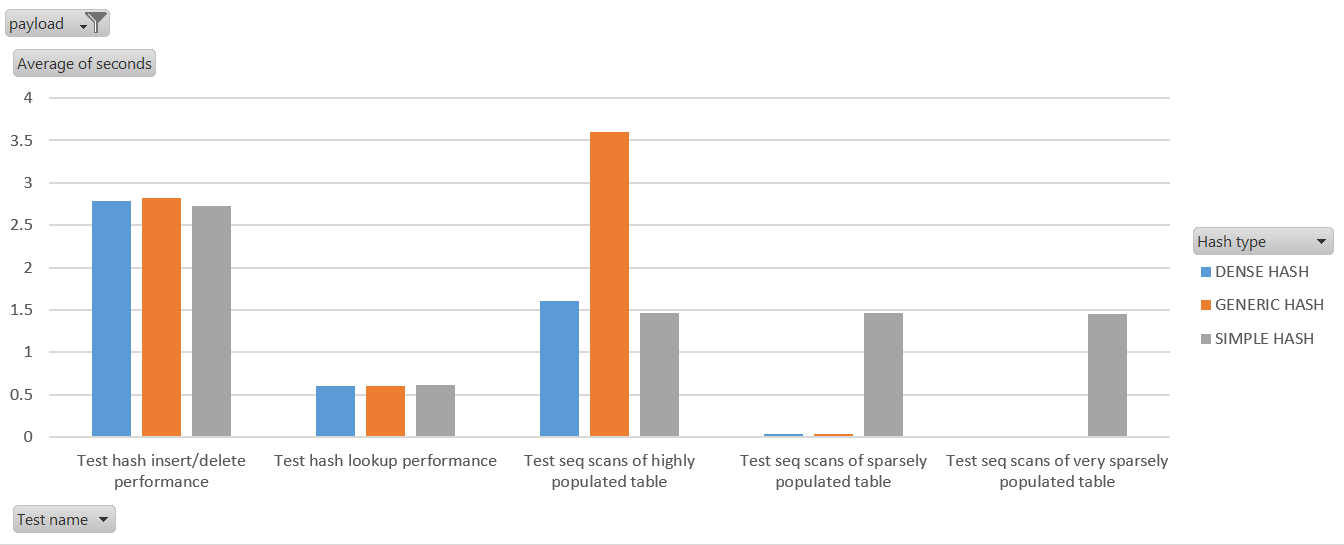
You can see from the attached dense_vs_generic_vs_simple.png that
dense hash is quite comparable to simplehash for inserts/deletes and
lookups. It's not quite as fast as simplehash at iterations when the
table is not bloated, but blows simplehash out the water when the
hashtables have become bloated due to having once contained a large
number of records but no longer do.
Anyway, unless there is some interest in me taking this idea further
then, due to the general feedback received on [1], I'm not planning on
pushing this any further. I'll leave the commitfest entry as is for
now to give others a chance to see this.
David
[1] https://postgr.es/m/CAApHDvowgRaQupC%3DL37iZPUzx1z7-N8deD7TxQSm8LR%2Bf4L3-A%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAApHDvpuzJTQNKQ_bnAccvi-68xuh%2Bv87B4P6ycU-UiN0dqyTg%40mail.gmail.com
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 26.4 KB |
| hashbench.tar.bz2 | application/octet-stream | 23.6 KB |
| densehash_for_lockreleaseall.patch | application/octet-stream | 51.3 KB |
In response to
- Re: Speed up transaction completion faster after many relations are accessed in a transaction at 2021-06-20 13:56:13 from David Rowley
Responses
- Re: Speed up transaction completion faster after many relations are accessed in a transaction at 2021-07-20 05:04:19 from David Rowley
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | houzj.fnst@fujitsu.com | 2021-07-12 08:00:52 | RE: Parallel INSERT SELECT take 2 |
| Previous Message | David Rowley | 2021-07-12 06:55:42 | Re: Speed up transaction completion faster after many relations are accessed in a transaction |