| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | More speedups for tuple deformation |
| Date: | 2025-12-28 09:04:25 |
| Message-ID: | CAApHDvpoFjaj3+w_jD5uPnGazaw41A71tVJokLDJg2zfcigpMQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Around this time last year I worked on a series of patches for v18 to
speed up tuple deformation. That involved about 5 separate patches,
the main 3 of which were 5983a4cff (CompactAttribute), db448ce5a
(faster offset aligning), and 58a359e58 (inline various deforming
loops). The latter of those 3 changed slot_deform_heap_tuple() to add
dedicated deforming loops for !slow mode and for tuples that don't
have the HEAP_HASNULL bit set.
When I was working on that, I wondered if it might be better to
precalculate the attcacheoff rather than doing it in the deforming
loop. I've finally written some code to do this, and I'm now ready to
share some results.
0001:
This introduces a function named TupleDescFinalize(), which must be
called after a TupleDesc has been created or changed. This function
pre-calculates the attcacheoff for all fixed-width attributes and
records the attnum of the first attribute without a cached offset (the
first varlena or cstring attribute). This allows the code in the
deforming loops which was setting CompactAttribute's attcacheoff to be
removed and allows a dedicated loop to process all attributes with an
attcacheoff before falling through to the loop that handles
non-attcacheoff attributes, which has to calculate the offset and
alignment manually. If the tuple has a NULL value before the last
attribute with a cached offset, then we can only use the attcacheoff
until the NULL attribute.
The expectation here is that knowing the offset beforehand is faster
than calculating it each time. Calculating the offset requires first
aligning the current offset according to the attributes attalign
value, then once we've called fetch_att() to get the Datum value, we
need to add the length of the attribute to skip forward to the next
attribute. There's not much opportunity for instruction-level
parallelism there due to the dependency on the previous calculation.
The primary optimisation in 0001 is that it adds a dedicated tight
loop to deform as many attributes with a cache offset as possible
before breaking out that loop to deform any remaining attributes
without using any cached offset.
0002:
After thinking about 0001 for a while, I wondered if we could do
better than resorting to having to check att_isnull() for every
attribute after we find the first NULL. What if the tuple has a NULL
quite early on, then no NULLs after that. It would be good if we
looked ahead in the tuple's NULL bitmap to identify exactly if and
when the next NULL attribute occurs and loop without checking
att_isnull() until that attribute.
Effectively, what I came up with was something like:
for (;;)
{
for(; attnum < nextNullAttr; attnum++)
{
// do fetch_att() without checking for NULLs
}
if (attnum >= natts)
break;
for(; attnum < nextNullSeqEnd; attnum++)
isnull[attnum] = true;
next_null_until(bp, attnum, natts, &nextNullAttr, &nextNullSeqEnd);
}
The next_null_until() function looks at the NULL bitmap starting at
attnum and sets nextNullAttr to the next NULL and nextNullSeqEnd to
the first attribute to the first non-NULL after the NULL. If there are
no more NULLs, then nextNullAttr is set to natts, which allows the
outer loop to complete.
Test #5 seems to do well with this code, but I wasn't impressed with
most of the other results. I'd have expected test #3 to improve with
this change, but it didn't.
0003:
In 0002 I added a dedicated loop that handles tuples without
HEAP_HASNULL. To see if it would make the performance any better I
made 0003, which gets rid of that dedicated loop. I hoped that
shrinking the code down might help performance. It didn't quite have
the effect I hoped for.
In each version, I experimented with having a dedicated deforming loop
which can only handle attbyval == true columns. If we know there are
no byref attributes, then fetch_att() can be inlined without the
branch that handles pointer types. That removes some branching
overhead and makes for a tighter loop with fewer instructions. When
this optimisation doesn't apply, there's a bit of extra overhead of
having to check for "attnum < firstByRefAttr".
Benchmarking:
To get an idea if doing this is a win performance-wise, I designed a
benchmark with various numbers of columns and various combinations of
fixed vs varlena types along with NULLs and no NULLs. There are 8
tests in total. For each of those 8 tests, I ran it with between 0
and 40 extra INT NOT NULL columns.
The tests are:
1. first col int not null, last col int not null
2. first col text not null, last col int not null
3. first col int null, last col int not null
4. first col text null, last col int not null
5. first col int not null, last col int null
6. first col text not null, last col int null
7. first col int null, last col int null
8. first col text null, last col int null
So, for example #1 would look like:
CREATE TABLE t1 (
c INT NOT NULL DEFAULT 0,
<extra 0-40 columns here>
a INT NOT NULL,
b INT NOT NULL DEFAULT 0
);
and #8 would be:
CREATE TABLE t1 (
c TEXT DEFAULT NULL,
<extra 0-40 columns here>
a INT NOT NULL,
b INT DEFAULT NULL
);
For each of the 8 tests, I ran with 0, 10, 20, 30 and 40 extra
columns, so 40 tests in total (8 tests * 5 for each variation of extra
columns).
Another benefit of 0001, besides using the fixed attcacheoff is that
since we know where the first NULL attribute is, we can keep deforming
without calling att_isnull() until we get to the first NULL attribute.
Currently in master, if the tuple has the HEAP_HASNULL bit set, then
the deforming code will call att_isnull for every attribute in the
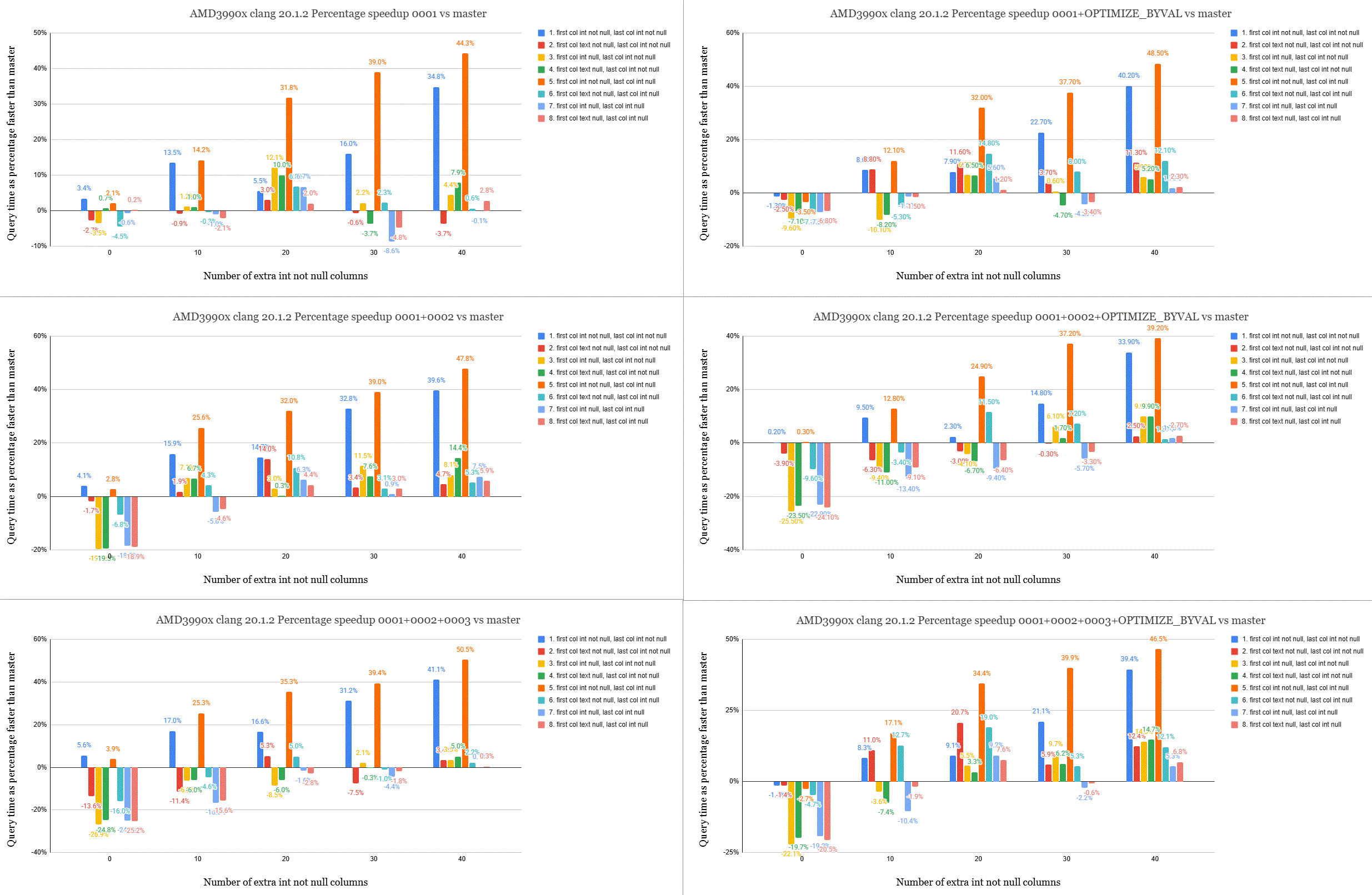
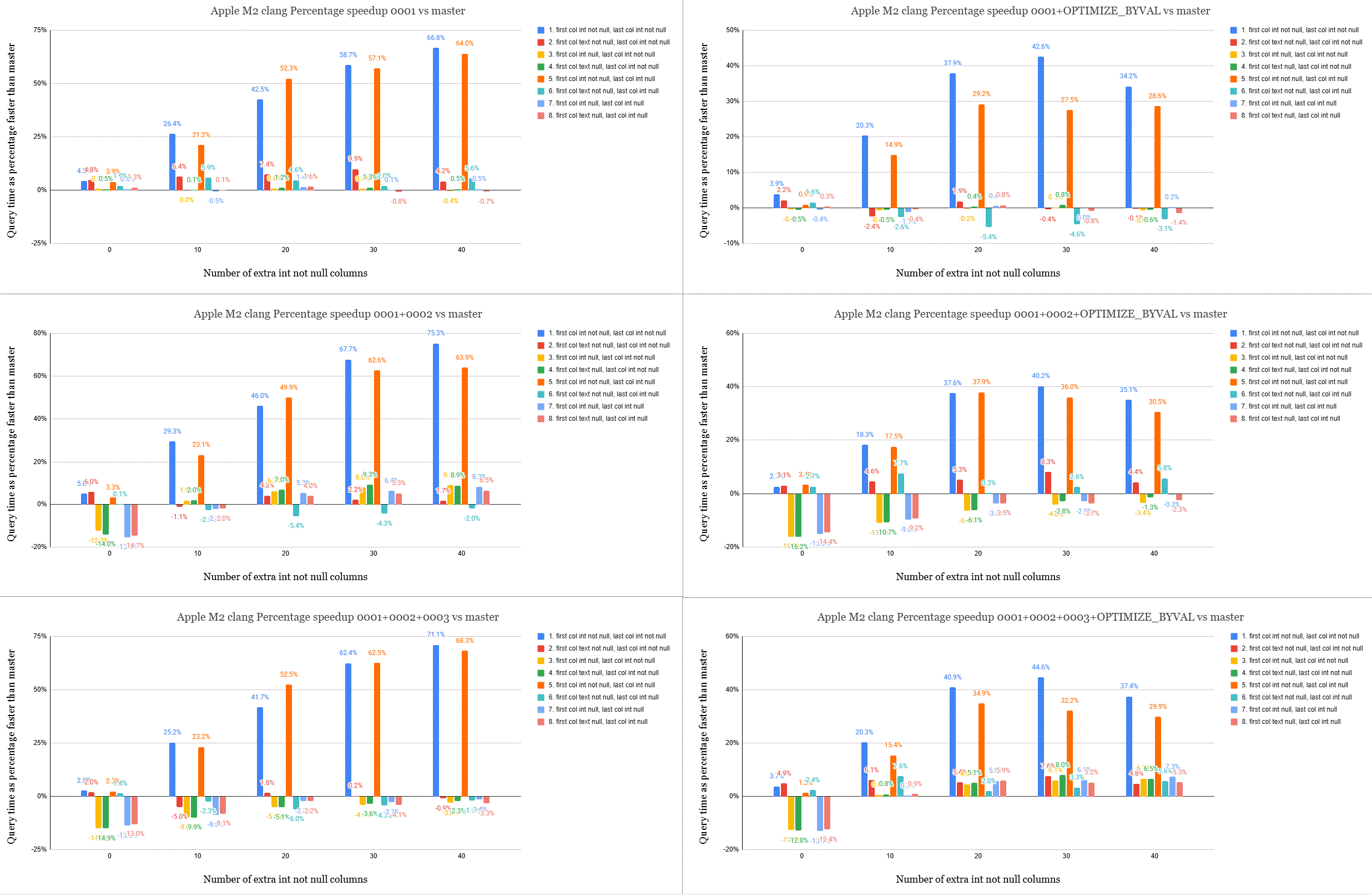
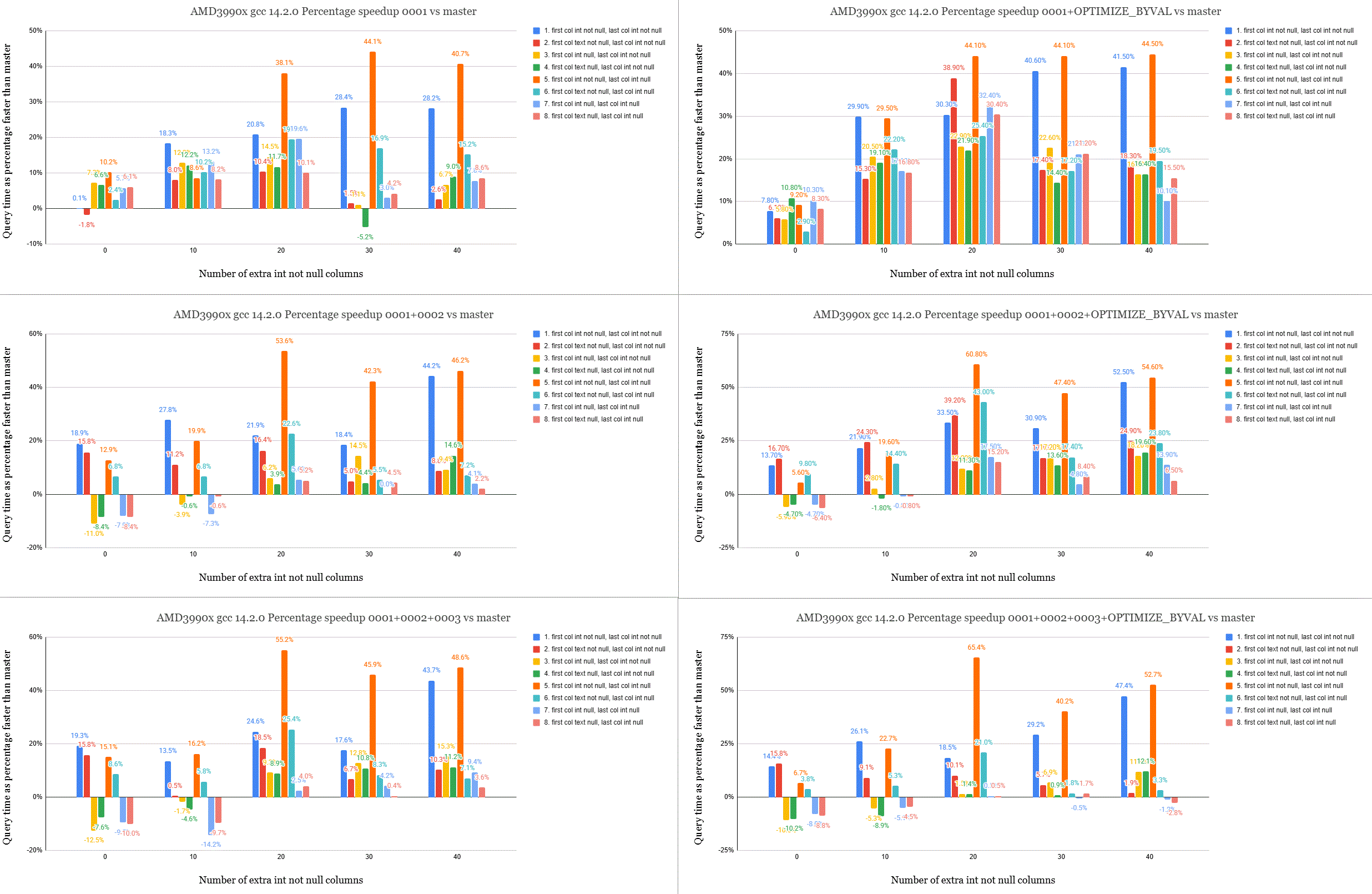
tuple. Test #5 should highlight this (you may notice the orange bar in
the attached graphs is commonly the test with the biggest speedup)
Now, not every query is bottlenecked on tuple deforming, so to try to
maximise the amount of tuple deforming that occurs relative to other
work, the query I ran was: SELECT sum(a) FROM t1; since the "a"
column is almost last, all prior attributes need to be deformed before
"a" can be.
I've tried to make the benchmark represent a large variety of
scenarios to see if there are any performance regressions. I've
benchmarked each patch with and without OPTIMIZE_BYVAL defined (the
additional byval-only attribute deformer loop). I tried with gcc and
with clang on my Zen 2 machine and also an Apple M2. Please see the
attached graphs which show the results of the SUM(a) query on a table
with 1 million rows.
Analysing the results, it's not really that clear which patch is best.
Which version works fastest seems to depend on the hardware. The AMD
Zen 2 machine with gcc does really well with 0001+OPTIMIZE_BYVAL as it
comes out an average of 21% faster and some tests are more than 44%
faster than master, and there are no performance regressions. With
clang on the same Zen2 machine the performance isn't the same. There
are a few regressions with the 0 extra column tests. On the Apple M2
tests #1 and #5 improve massively. The other tests don't improve
nearly as much and with certain patches a few regress slightly.
Please see the attached gifs which show 6 graphs each. Top is the
results of 0001, the middle row is 0001+0002 and the bottom row
0001+0002+0003. The left column is without OPTIMIZE_BYVAL and the
right column is with. The percentage shown is the query time speedup
the patched version gives over master.
Things still to do:
* More benchmarking is needed. I've not yet completed the benchmarks
on my Zen4 machine. No Intel hardware has been tested at all. I don't
really have any good Intel hardware to test with. Maybe someone else
would like to help? Script is attached.
* I've not looked at the JIT deforming code. At the moment the code
won't even compile with LLVM enabled because I've removed the
TTS_FLAG_SLOW flag. It's possible I'll have to adjust the JIT
deforming code or consider keeping TTS_FLAG_SLOW.
I'll add this patch to the January commitfest.
David
| Attachment | Content-Type | Size |
|---|---|---|
| v1-0001-Precalculate-CompactAttribute-s-attcacheoff.patch | text/plain | 71.0 KB |
| amd3990x_clang_results.gif | image/gif | 210.6 KB |
| apple_m2_results.gif | image/gif | 197.6 KB |
| amd3990x_gcc_results.gif | image/gif | 245.9 KB |
| v1-0002-Experimental-code-for-better-NULL-handing-in-tupl.patch | text/plain | 8.3 KB |
| v1-0003-Experiment-without-a-dedicated-hasnulls-loop.patch | text/plain | 3.7 KB |
| deform_test.sh.txt | text/plain | 1.3 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | zengman | 2025-12-28 09:12:32 | [Patch] timezone/zic.c: Fix file handle leak in dolink() |
| Previous Message | zengman | 2025-12-28 08:42:22 | Re:Avoid corrupting DefElem nodes when parsing publication_names and publish options |
{kind=link}
{kind=link}
{kind=link}