| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Reducing the chunk header sizes on all memory context types |
| Date: | 2022-07-12 05:01:18 |
| Message-ID: | CAApHDvpjauCRXcgcaL6+e3eqecEHoeRm9D-kcbuvBitgPnW=vw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Over on [1], I highlighted that 40af10b57 (Use Generation memory
contexts to store tuples in sorts) could cause some performance
regressions for sorts when the size of the tuple is exactly a power of
2. The reason for this is that the chunk header for generation.c
contexts is 8 bytes larger (on 64-bit machines) than the aset.c chunk
header. This means that we can store fewer tuples per work_mem during
the sort and that results in more batches being required.
As I write this, this regression is still marked as an open item for
PG15 in [2]. So I've been working on this to try to assist the
discussion about if we need to do anything about that for PG15.
Over on [3], I mentioned that Andres came up with an idea and a
prototype patch to reduce the chunk header size across the board by
storing the context type in the 3 least significant bits in a uint64
header.
I've taken Andres' patch and made some quite significant changes to
it. In the patch's current state, the sort performance regression in
PG15 vs PG14 is fixed. The generation.c context chunk header has been
reduced to 8 bytes from the previous 24 bytes as it is in master.
aset.c context chunk header is now 8 bytes instead of 16 bytes.
We can use this 8-byte chunk header by using the remaining 61-bits of
the uint64 header to encode 2 30-bit values to store the chunk size
and also the number of bytes we must subtract from the given pointer
to find the block that the chunk is stored on. Once we have the
block, we can find the owning context by having a pointer back to the
context from the block. For memory allocations that are larger than
what can be stored in 30 bits, the chunk header gets an additional two
Size fields to store the chunk_size and the block offset. We can tell
the difference between the 2 chunk sizes by looking at the spare 1-bit
the uint64 portion of the header.
Aside from speeding up the sort case, this also seems to have a good
positive performance impact on pgbench read-only workload with -M
simple. I'm seeing about a 17% performance increase on my AMD
Threadripper machine.
master + Reduced Memory Context Chunk Overhead
drowley(at)amd3990x:~$ pgbench -S -T 60 -j 156 -c 156 -M simple postgres
tps = 1876841.953096 (without initial connection time)
tps = 1919605.408254 (without initial connection time)
tps = 1891734.480141 (without initial connection time)
Master
drowley(at)amd3990x:~$ pgbench -S -T 60 -j 156 -c 156 -M simple postgres
tps = 1632248.236962 (without initial connection time)
tps = 1615663.151604 (without initial connection time)
tps = 1602004.146259 (without initial connection time)
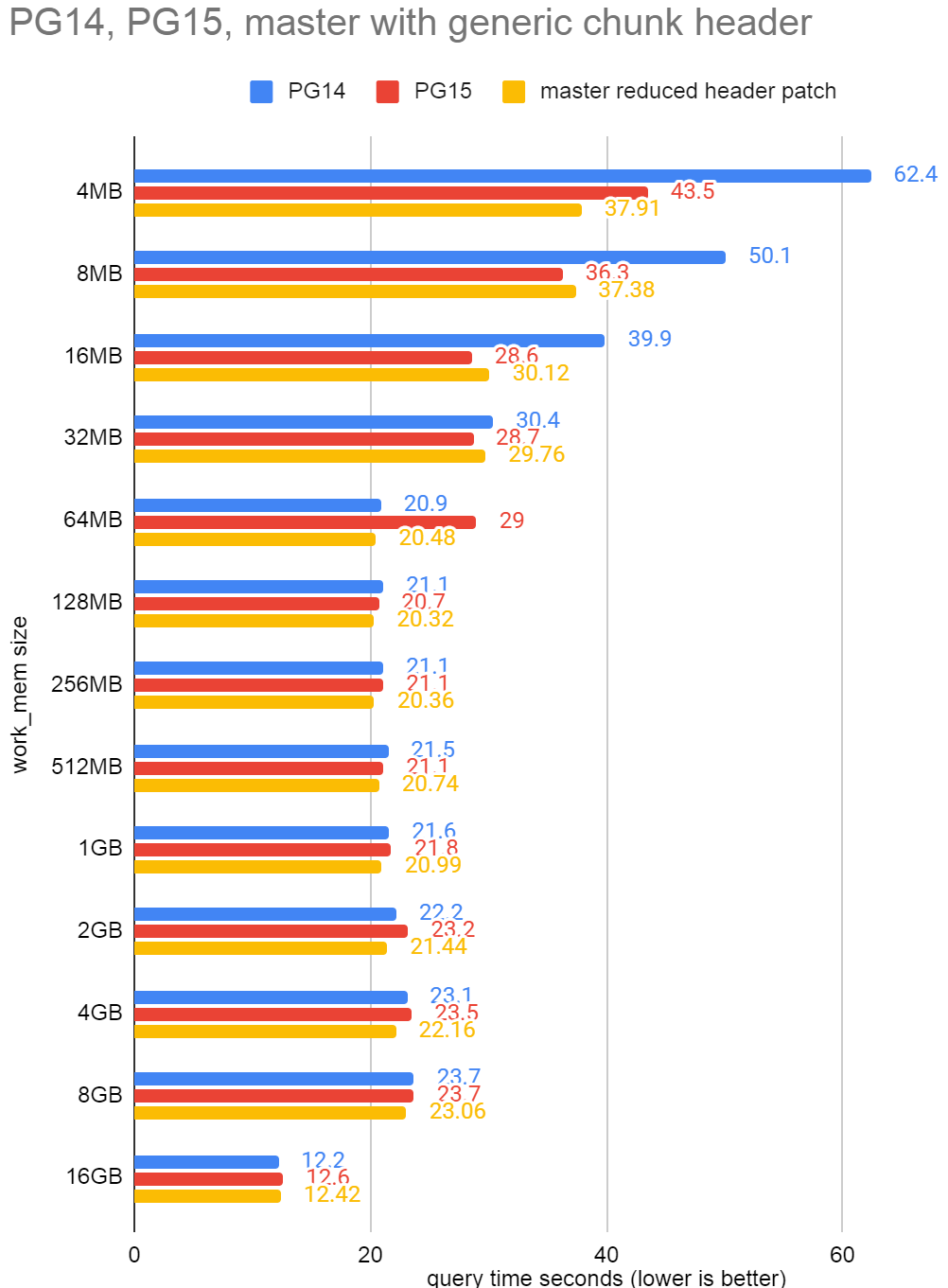
The attached .png file shows the same results for PG14 and PG15 as I
showed in the blog [4] where I discovered the regression and adds the
results from current master + the attached patch. See bars in orange.
You can see that the regression at 64MB work_mem is fixed. Adding some
tracing to the sort shows that we're now doing 671745 tuples per batch
instead of 576845 tuples. This reduces the number of batches from 245
down to 210.
Drawbacks:
There is at least one. It might be major; to reduce the AllocSet chunk
header from 16 bytes down to 8 bytes I had to get rid of the freelist
pointer that was reusing the "aset" field in the chunk header struct.
This works now by storing that pointer in the actual palloc'd memory.
This could lead to pretty hard-to-trace bugs if we have any code that
accidentally writes to memory after pfree. The slab.c context already
does this, but that's far less commonly used. If we decided this was
unacceptable then it does not change anything for the generation.c
context. The chunk header will still be 8 bytes instead of 24 there.
So the sort performance regression will still be fixed.
To improve this situation, we might be able code it up so that
MEMORY_CONTEXT_CHECKING builds add an additional freelist pointer to
the header and also write it to the palloc'd memory then verify
they're set to the same thing when we reuse a chunk from the freelist.
If they're not the same then MEMORY_CONTEXT_CHECKING builds could
either spit out a WARNING or ERROR for this case. That would make it
pretty easy for developers to find their write after pfree bugs. This
might actually be better than the Valgrind detection method that we
have for this today.
Patch:
I've attached the WIP patch. At this stage, I'm more looking for a
design review. I'm not aware of any bugs, but I am aware that I've not
tested with Valgrind. I've not paid a great deal of attention to
updating the Valgrind macros at all.
I'll add this to the September CF. I'm submitting now due to the fact
that we still have an open item in PG15 for the sort regression and
the existence of this patch might cause us to decide whether we can
defer fixing that to PG16 by way of the method in this patch, or
revert 40af10b57.
Benchmark code in [5].
David
[1] https://www.postgresql.org/message-id/CAApHDvqXpLzav6dUeR5vO_RBh_feHrHMLhigVQXw9jHCyKP9PA%40mail.gmail.com
[2] https://wiki.postgresql.org/wiki/PostgreSQL_15_Open_Items
[3] https://www.postgresql.org/message-id/CAApHDvowHNSVLhMc0cnovg8PfnYQZxit-gP_bn3xkT4rZX3G0w%40mail.gmail.com
[4] https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/speeding-up-sort-performance-in-postgres-15/ba-p/3396953
[5] https://www.postgresql.org/message-id/attachment/134161/sortbench_varcols.sh
| Attachment | Content-Type | Size |
|---|---|---|
| v1-0001-WIP-Reduce-memory-context-overheads.patch | text/plain | 109.6 KB |
| 10gb_sort_bench_2022-07-12.png | image/png | 97.9 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Rowley | 2022-07-12 05:15:08 | Re: PG15 beta1 sort performance regression due to Generation context change |
| Previous Message | Nikolay Shaplov | 2022-07-12 04:47:22 | Re: [PATCH] New [relation] option engine |
{kind=link}