Re: Hybrid Hash/Nested Loop joins and caching results from subplans
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: Hybrid Hash/Nested Loop joins and caching results from subplans |
| Date: | 2020-10-20 09:30:55 |
| Message-ID: | CAApHDvoiNQG9YUiSbVav-5z0FXJUN3k75fK4ooU7Ld7xGvz2xQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Tue, 15 Sep 2020 at 12:58, David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
>
> I've not done any further work to shift the patch any further in that
> direction yet. I know it's going to be quite a bit of work and it
> sounds like there are still objections in both directions. I'd rather
> everyone agreed on something before I go to the trouble of trying to
> make something committable with Andres' way.
I spent some time converting the existing v8 to move the caching into
the Nested Loop node instead of having an additional Result Cache node
between the Nested Loop and the inner index scan. To minimise the size
of this patch I've dropped support for caching Subplans, for now.
I'd say the quality of this patch is still first draft. I just spent
today getting some final things working again and spent a few hours
trying to break it then another few hours running benchmarks on it and
comparing it to the v8 patch, (v8 uses a separate Result Cache node).
I'd say most of the patch is pretty good, but the changes I've made in
nodeNestloop.c will need to be changed a bit. All the caching logic
is in a new file named execMRUTupleCache.c. nodeNestloop.c is just a
consumer of this. It can detect if the MRUTupleCache was a hit or a
miss depending on which slot the tuple is returned in. So far I'm just
using that to switch around the projection info and join quals for the
ones I initialised to work with the MinimalTupleSlot from the cache.
I'm not yet sure exactly how this should be improved, I just know
what's there is not so great.
So far benchmarking shows there's still a regression from the v8
version of the patch. This is using count(*). An earlier test [1] did
show speedups when we needed to deform tuples returned by the nested
loop node. I've not yet repeated that test again. I was disappointed
to see v9 slower than v8 after having spent about 3 days rewriting the
patch
The setup for the test I did was:
create table hundredk (hundredk int, tenk int, thousand int, hundred
int, ten int, one int);
insert into hundredk select x%100000,x%10000,x%1000,x%100,x%10,1 from
generate_Series(1,100000) x;
create table lookup (a int);
insert into lookup select x from generate_Series(1,100000)x,
generate_Series(1,100);
create index on lookup(a);
vacuum analyze lookup, hundredk;
I then ran a query like;
select count(*) from hundredk hk inner join lookup l on hk.thousand = l.a;
in pgbench for 60 seconds and then again after swapping the join
column to hk.hundred, hk.ten and hk.one so that fewer index lookups
were performed and more cache hits were seen.
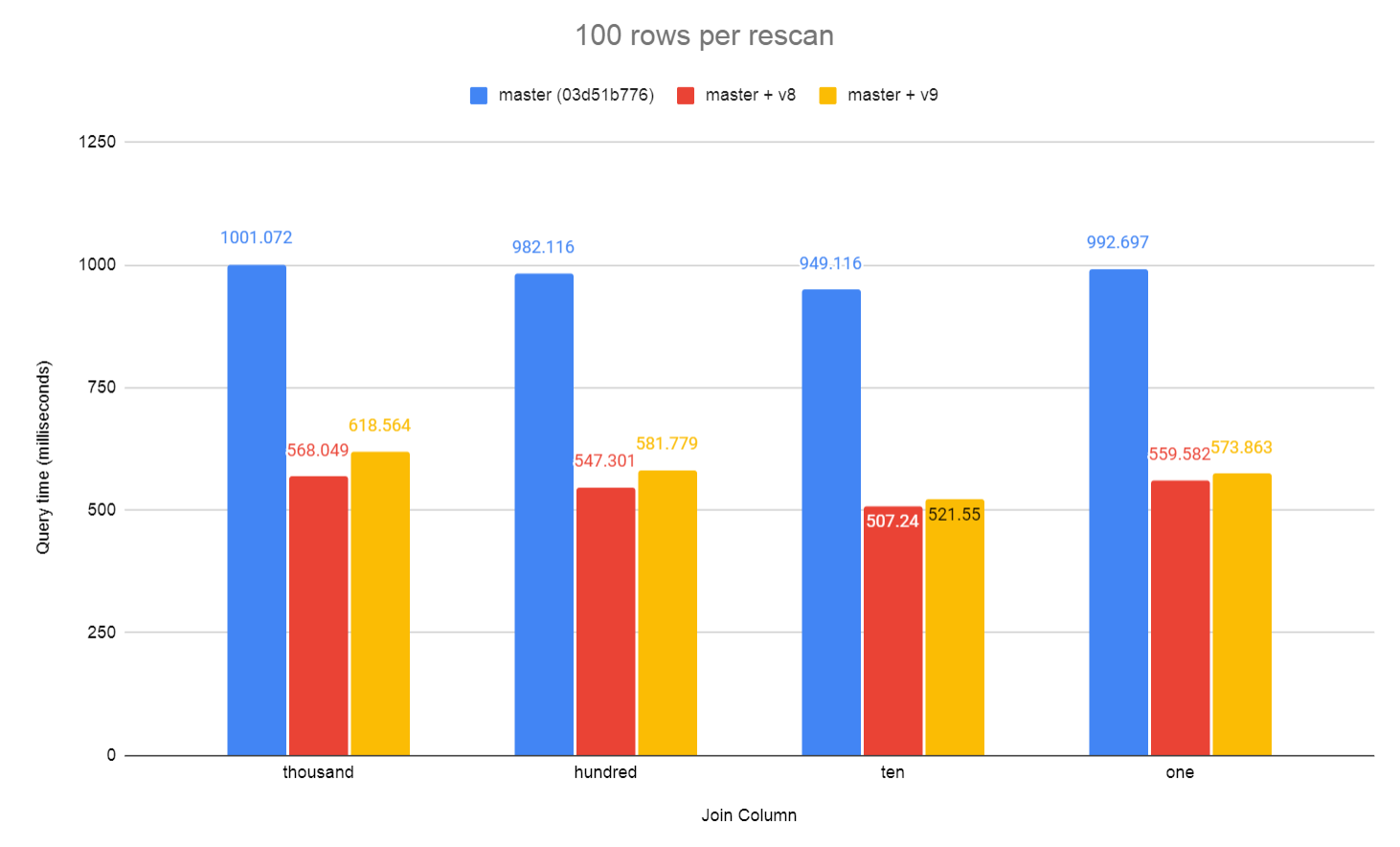
I did have enable_mergejoin = off when testing v8 and v9 on this test.
The planner seemed to favour merge join over nested loop without that.
Results in hundred_rows_per_rescan.png.
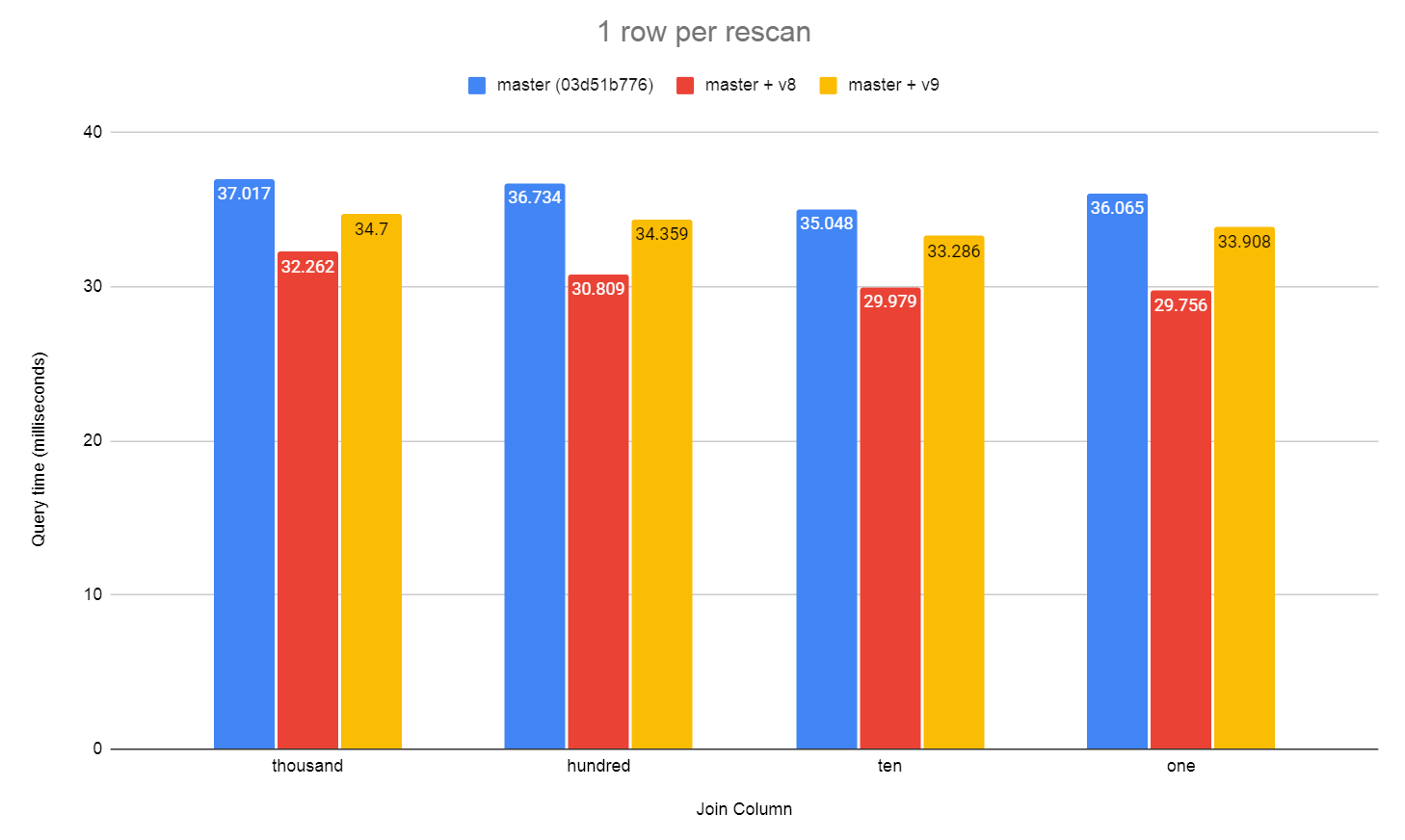
I then reduced the lookup table so it only has 1 row to lookup instead
of 100 for each value.
truncate lookup;
insert into lookup select x from generate_Series(1,100000)x;
vacuum analyze lookup;
and ran the tests again. Results in one_row_per_rescan.png.
I also wanted to note that these small scale tests are not the best
case for this patch. I've seen much more significant gains when an
unpatched Hash join's hash table filled the L3 cache and started
having to wait for RAM. Since my MRU cache was much smaller than the
Hash join's hash table, it performed about 3x faster. What I'm trying
to focus on here is the regression from v8 to v9. It seems to cast a
bit more doubt as to whether v9 is any better than v8.
I really would like to start moving this work towards a commit in the
next month or two. So any comments about v8 vs v9 would be welcome as
I'm still uncertain which patch is best to pursue.
David
| Attachment | Content-Type | Size |
|---|---|---|
| v9-0001-Allow-estimate_num_groups-to-pass-back-further-de.patch | text/plain | 8.8 KB |
| v9-0002-Allow-users-of-simplehash.h-to-perform-direct-del.patch | text/plain | 3.5 KB |
| v9-0003-Allow-parameterized-Nested-Loops-to-cache-tuples-.patch | text/plain | 138.0 KB |
|
image/png | 55.9 KB |
|
image/png | 53.1 KB |
In response to
- Re: Hybrid Hash/Nested Loop joins and caching results from subplans at 2020-09-15 00:58:40 from David Rowley
Responses
- Re: Hybrid Hash/Nested Loop joins and caching results from subplans at 2020-11-02 07:43:54 from David Rowley
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | John Naylor | 2020-10-20 09:33:43 | Re: speed up unicode normalization quick check |
| Previous Message | Simon Riggs | 2020-10-20 09:30:03 | Re: Is Recovery actually paused? |