| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Amit Kapila <amit(dot)kapila16(at)gmail(dot)com>, Thomas Munro <thomas(dot)munro(at)gmail(dot)com>, Ranier Vilela <ranier(dot)vf(at)gmail(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Seq Scan vs kernel read ahead |
| Date: | 2020-06-22 04:54:22 |
| Message-ID: | CAApHDvo+LEGKMcavOiPYK8NEbgP-LrXns2TJ1n_XNRJVE9X+Cw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Fri, 19 Jun 2020 at 14:10, David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> Here's a patch which caps the maximum chunk size to 131072. If
> someone doubles the page size then that'll be 2GB instead of 1GB. I'm
> not personally worried about that.
>
> I tested the performance on a Windows 10 laptop using the test case from [1]
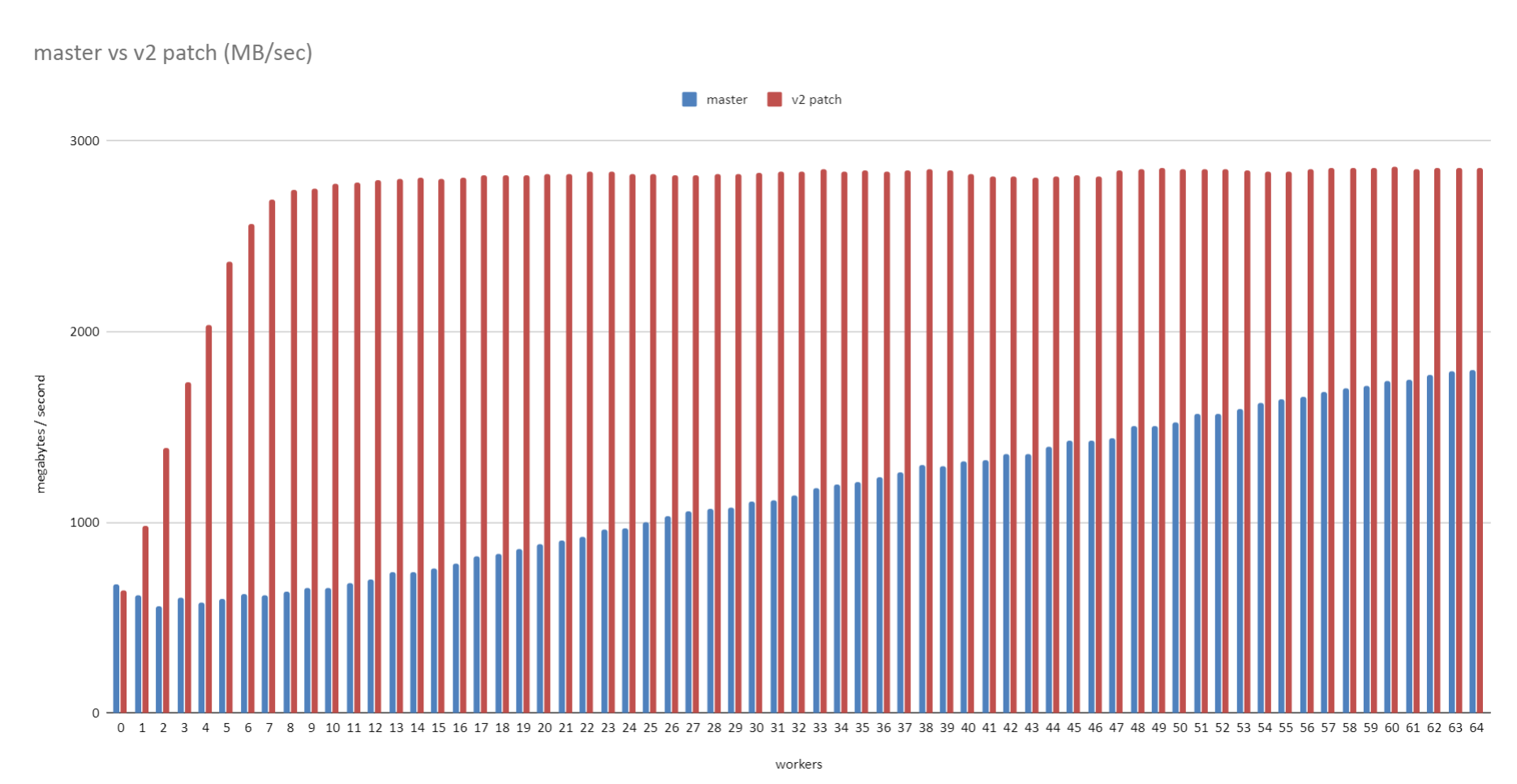
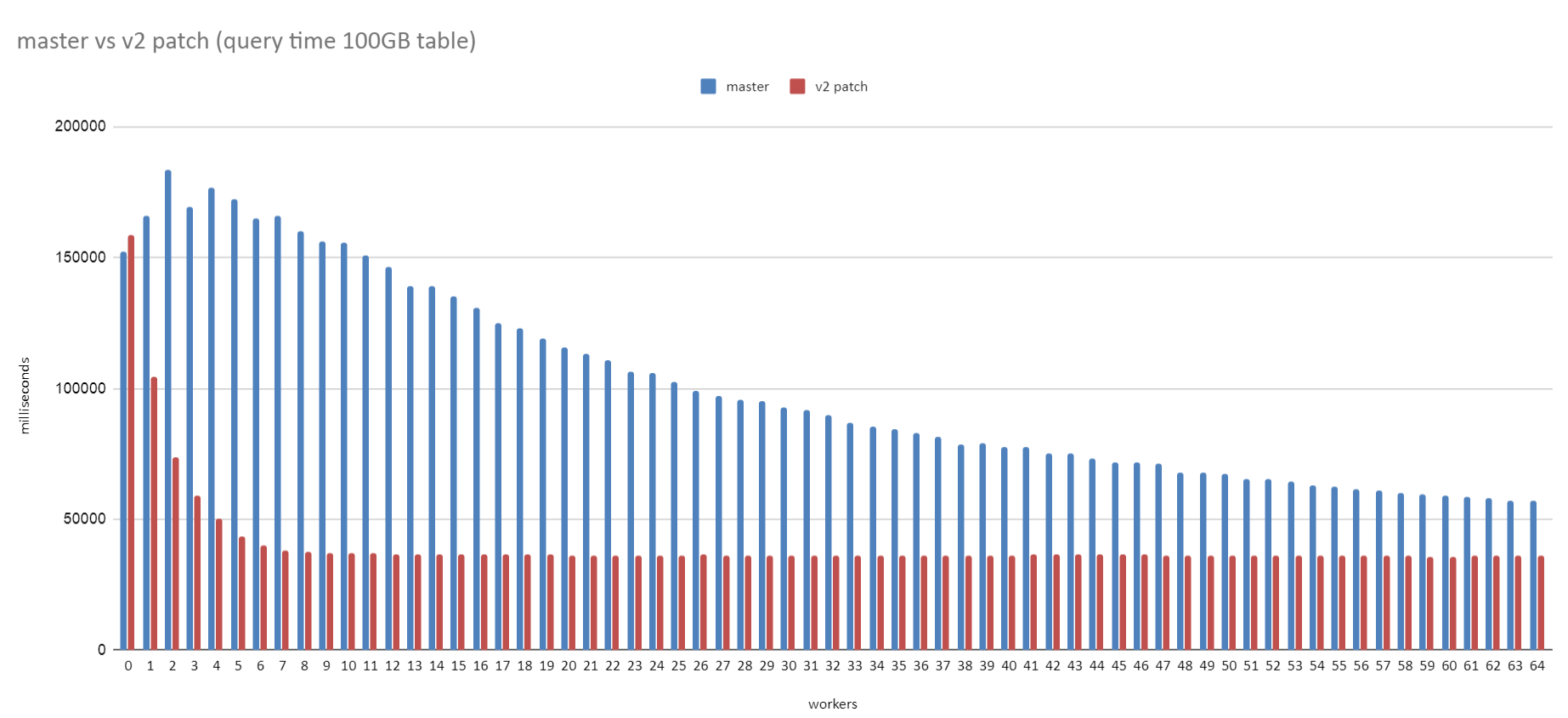
I also tested this an AMD machine running Ubuntu 20.04 on kernel
version 5.4.0-37. I used the same 100GB table I mentioned in [1], but
with the query "select * from t where a < 0;", which saves having to
do any aggregate work.
There seems to be quite a big win with Linux too. See the attached
graphs. Both graphs are based on the same results, just the MB/sec
one takes the query time in milliseconds and converts that into MB/sec
for the 100 GB table. i.e. 100*1024/(<milliseconds> /1000)
The machine is a 64core / 128 thread AMD machine (3990x) with a 1TB
Samsung 970 Pro evo plus SSD, 64GB RAM
| Attachment | Content-Type | Size |
|---|---|---|
| v2_patch_mbsec.png | image/png | 105.0 KB |
| v2_patch_millisec.png | image/png | 79.6 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Amit Kapila | 2020-06-22 05:05:47 | Backpatch b61d161c14 |
| Previous Message | Sumanta Mukherjee | 2020-06-22 04:53:33 | Re: I'd like to discuss scaleout at PGCon |
{kind=link}
{kind=link}