| From: | Thomas Munro <thomas(dot)munro(at)gmail(dot)com> |
|---|---|
| To: | Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Cc: | Ian Lawrence Barwick <barwick(at)gmail(dot)com>, Justin Pryzby <pryzby(at)telsasoft(dot)com>, vignesh C <vignesh21(at)gmail(dot)com>, Greg Nancarrow <gregn4422(at)gmail(dot)com>, Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Full Hash Join |
| Date: | 2023-03-30 22:55:53 |
| Message-ID: | CA+hUKGJjN-vJXa3P9=-h4XU-Ty-h7WPpzzXJnA2b4NzitdYFgg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Fri, Mar 31, 2023 at 8:23 AM Melanie Plageman
<melanieplageman(at)gmail(dot)com> wrote:
> I understand the scenario you are thinking of, however, I question how
> those incorrectly formed tuples would ever be returned by the query. The
> hashjoin would only start to shutdown once enough tuples had been
> emitted to satisfy the limit, at which point, those tuples buffered in
> p0 may be emitted by this worker but wouldn't be included in the query
> result, no?
Yeah, I think I must have been confused by that too early on. The
thing is, Gather asks every worker process for n tuples so that any
one of them could satisfy the LIMIT if required, but it's unknown
which process's output the Gather node will receive first (or might
make it into intermediate nodes and affect the results). I guess to
see bogus unmatched tuples actually escaping anywhere (with the
earlier patches) you'd need parallel leader off + diabolical
scheduling?
I thought about 3 solutions before settling on #3: (1)
Hypothetically, P1 could somehow steal/finish P0's work, but our
executor has no mechanism for anything like that. (2) P0 isn't
allowed to leave the probe early, instead it has to keep going but
throw away the tuples it'd normally emit, so we are sure we have all
the match bits in shared memory. (3) P0 seizes responsibility for
emitting those tuples, but then does nothing because the top level
executor doesn't want more tuples, which in practice looks like a flag
telling everyone else not to bother.
Idea #1 would probably require shared address space (threads) and a
non-recursive executor, as speculated about a few times before, and
that type of magic could address several kinds of deadlock risks, but
in this case we still wouldn't want to do that even if we could; it's
work that is provably (by idea #3's argument) a waste of time. Idea
#2 is a horrible pessimisation of idea #1 within our existing executor
design, but it helped me think about what it really means to be
authorised to throw away tuples from on high.
> I suppose even if what I said is true, we do not want the hashjoin node
> to ever produce incorrect tuples. In which case, your fix seems correct to me.
Yeah, that's a good way to put it.
> > The last things I'm thinking about now: Are the planner changes
> > right?
>
> I think the current changes are correct. I wonder if we have to change
> anything in initial/final_cost_hashjoin to account for the fact that
> for a single batch full/right parallel hash join, part of the
> execution is serial. And, if so, do we need to consider the estimated
> number of unmatched tuples to be emitted?
I have no idea how to model that, and I'm assuming the existing model
should continue to work as well as it does today "on average". The
expected number of tuples will be the same across all workers, it's
just an unfortunate implementation detail that the distribution sucks
(but is still much better than a serial plan). I wondered if
get_parallel_divisor() might provide some inspiration but that's
dealing with a different problem: a partial extra process that will
take some of the work (ie tuples) away from the other processes, and
that's not the case here.
> > Are the tests enough?
>
> So, the tests currently in the patch set cover the unmatched tuple scan
> phase for single batch parallel full hash join. I've attached the
> dumbest possible addition to that which adds in a multi-batch full
> parallel hash join case. I did not do any checking to ensure I picked
> the case which would add the least execution time to the test, etc.
Thanks, added.
I should probably try to figure out how to get the join_hash tests to
run with smaller tables. It's one of the slower tests and this adds
to it. I vaguely recall it was hard to get the batch counts to be
stable across the build farm, which makes me hesitant to change the
tests but perhaps I can figure out how to screw it down...
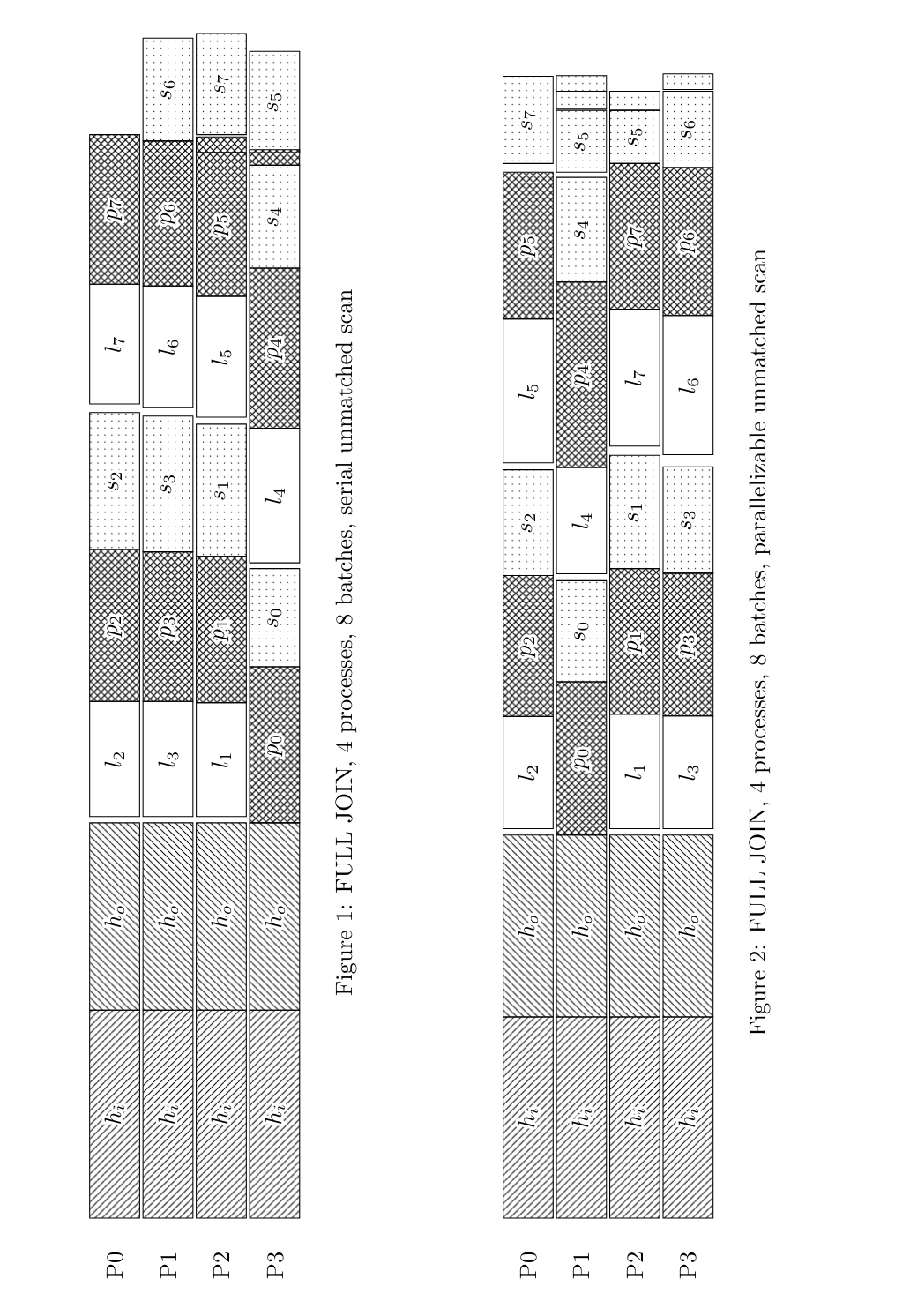
I decided to drop the scan order change for now (0001 in v13). Yes,
it's better than what we have now, but it seems to cut off some other
possible ideas to do even better, so it feels premature to change it
without more work. I changed the parallel unmatched scan back to
being as similar as possible to the serial one for now.
I committed the main patch.
Here are a couple of ideas that came up while working on this, for future study:
* the "opportunistic help" thing you once suggested to make it a
little fairer in multi-batch cases. Quick draft attached, for future
experimentation. Seems to work pretty well, but could definitely be
tidier and there may be holes in it. Pretty picture attached.
* should we pass HJ_FILL_INNER(hjstate) into a new parameter
fill_inner to ExecHashJoinImpl(), so that we can make specialised hash
join routines for the yes and no cases, so that we can remove
branching and memory traffic related to match bits?
* could we use tagged pointers to track matched tuples? Tuples are
MAXALIGNed, so bits 0 and 1 of pointers to them are certainly always
0. Perhaps we could use bit 0 for "matched" and bit 1 for "I am not
the last tuple in my chain, you'll have to check the next one too".
Then you could scan for unmatched without following many pointers, if
you're lucky. You could skip the required masking etc for that if
!fill_inner.
* should we use software prefetching to smooth over the random memory
order problem when you do have to follow them? Though it's hard to
prefetch chains, here we have an array full of pointers at least to
the first tuples in each chain. This probably goes along with the
general hash join memory prefetching work that I started a couple of
years back and need to restart for 17.
* this idea is probably stupid overkill, but it's something that
v13-0001 made me think about: could it be worth the effort to sample a
fraction of the match bits in the hash table buckets (with the scheme
above), and determine whether you'll be emitting a high fraction of
the tuples, and then switch to chunk based so that you can do it in
memory order if so? That requires having the match flag in *two*
places, which seems silly; you'd need some experimental evidence that
any of this is worth bothering with
* currently, the "hash inner" phase only loads tuples into batch 0's
hash table (the so-called "hybrid Grace" technique), but if there are
(say) 4 processes, you could actually load batches 0-3 into memory
during that phase, to avoid having to dump 1-3 out to disk and then
immediately load them back in again; you'd get to skip "l1", "l2",
"l3" on those diagrams and finish a good bit faster
| Attachment | Content-Type | Size |
|---|---|---|
| more-parallel.png | image/png | 452.9 KB |
| 0001-Make-multi-batch-Parallel-Hash-Full-Join-fairer.patch | text/x-patch | 8.5 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Lane | 2023-03-30 23:25:22 | Re: Thoughts on using Text::Template for our autogenerated code? |
| Previous Message | Peter Smith | 2023-03-30 22:30:43 | Re: Support logical replication of DDLs |
{kind=link}