Re: Speed up COPY FROM text/CSV parsing using SIMD
| From: | KAZAR Ayoub <ma_kazar(at)esi(dot)dz> |
|---|---|
| To: | Neil Conway <neil(dot)conway(at)gmail(dot)com> |
| Cc: | Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com>, Manni Wood <manni(dot)wood(at)enterprisedb(dot)com>, Nathan Bossart <nathandbossart(at)gmail(dot)com>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Shinya Kato <shinya11(dot)kato(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Speed up COPY FROM text/CSV parsing using SIMD |
| Date: | 2026-01-22 19:32:43 |
| Message-ID: | CA+K2Rumkq2biMOaS3XD_x2M6vwy+yPpraeo3oMvarjVw5OJfiw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Wed, Jan 21, 2026 at 9:50 PM Neil Conway <neil(dot)conway(at)gmail(dot)com> wrote:
> A few suggestions:
>
> * I'm curious if we'll see better performance on large inputs if we flush
> to `line_buf` periodically (e.g., at least every few thousand bytes or so).
> Otherwise we might see poor data cache behavior if large inputs with no
> control characters get evicted before we've copied them over. See the
> approach taken in escape_json_with_len() in utils/adt/json.c
>
Hello Neil, thanks for the suggestions!
This might be true as the json code considers it, i'll take a look later.
>
> * Did you compare the approach taken in the patch with a simpler approach
> that just does
>
> if (!(vector8_has(chunk, '\\') ||
> vector8_has(chunk, '\r') ||
> vector8_has(chunk, '\n') /* and so on, accounting for CSV / escapec
> / quotec stuff */))
> {
> /* skip chunk */
> }
>
> That's roughly what we do elsewhere (e.g., escape_json_with_len). It has
> the advantage of being more readable, along with potentially having fewer
> data dependencies.
>
This is true and also similar to the concerns of the very first patches
where i tried to just replace the special chars detection by something less
dependent but I missed vector8_has.
I have tried this now and here are my thoughts and results:
v5: the simplest of all, we take a chunk, detect any special character, if
it's clean then skip it all, otherwise fallback to scalar WITHOUT advancing
to the first special char found, this is mentioned just for reference and
comparison.
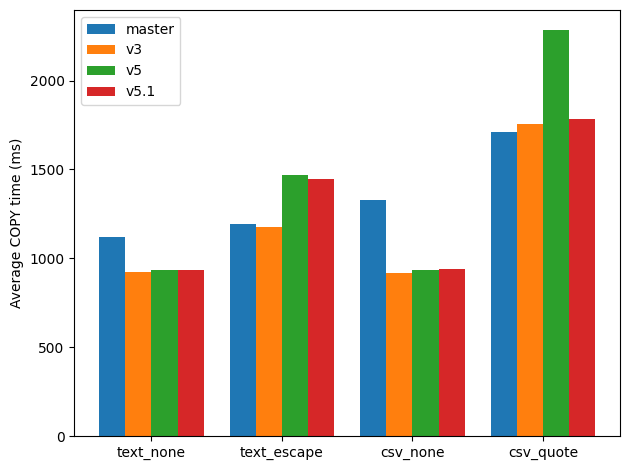
Numbers compared to master:
text, no special: +16.8%
text, 1/3 special: -21.3%
csv, no special: +29.5%
csv, 1/3 special: -33.5%
v5.1: Take a chunk, if its clean of specials, skip it, if not process the
whole chunk byte-by-byte, retry the same thing for next chunk if it's fully
skippable and so on...
Numbers:
text, no special: +16.5%
text, 1/3 special: -20.1% (weird) ; but overall the idea is clear maybe.
csv, no special: +29.4%
csv, 1/3 special: -4.4%
For files of 1/3 specials it's almost always terrible to consider simd
because it will always fall back to scalar without even advancing to the
first special character, even for something less than 1/3 i think it would
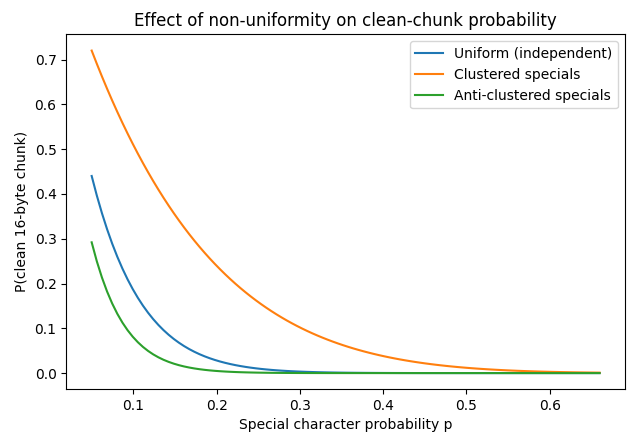
be same case, i attached an extremely simple analysis on probability of
having a 16 byte clean chunk depending on data we have.
Attached also is an overall comparison graph between master, v3, v5.1 (with
patch)
Regards,
Ayoub
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 42.3 KB |
|
image/png | 17.1 KB |
| v5.1-0001-Simple-heuristic-for-SIMD-COPY-FROM.patch | text/x-patch | 2.4 KB |
In response to
- Re: Speed up COPY FROM text/CSV parsing using SIMD at 2026-01-21 20:49:59 from Neil Conway
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Joao Foltran | 2026-01-22 19:41:13 | Re: [BUG] [PATCH] Allow physical replication slots to recover from archive after invalidation |
| Previous Message | Jim Jones | 2026-01-22 19:27:11 | Re: ALTER TABLE: warn when actions do not recurse to partitions |