| From: | Alena Rybakina <lena(dot)ribackina(at)yandex(dot)ru> |
|---|---|
| To: | Peter Geoghegan <pg(at)bowt(dot)ie> |
| Cc: | Marcos Pegoraro <marcos(at)f10(dot)com(dot)br>, Alena Rybakina <a(dot)rybakina(at)postgrespro(dot)ru>, Andrey Lepikhov <a(dot)lepikhov(at)postgrespro(dot)ru>, pgsql-hackers(at)postgresql(dot)org, teodor(at)sigaev(dot)ru |
| Subject: | Re: POC, WIP: OR-clause support for indexes |
| Date: | 2023-06-27 13:19:48 |
| Message-ID: | 7829312a-eb6b-b9ba-9719-71c9bc410884@yandex.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 26.06.2023 06:18, Peter Geoghegan wrote:
> On Sun, Jun 25, 2023 at 6:48 PM Alena Rybakina<lena(dot)ribackina(at)yandex(dot)ru> wrote:
>> I finished writing the code patch for transformation "Or" expressions to "Any" expressions.
> This seems interesting to me. I'm currently working on improving
> nbtree's "native execution of ScalarArrayOpExpr quals" (see commit
> 9e8da0f7 for background information). That is relevant to what you're
> trying to do here.
>
> Right now nbtree's handling of ScalarArrayOpExpr is rather
> inefficient. The executor does pass the index scan an array of
> constants, so the whole structure already allows the nbtree code to
> execute the ScalarArrayOpExpr in whatever way would be most efficient.
> There is only one problem: it doesn't really try to do so. It more or
> less just breaks down the large ScalarArrayOpExpr into "mini" queries
> -- one per constant. Internally, query execution isn't significantly
> different to executing many of these "mini" queries independently. We
> just sort and deduplicate the arrays. We don't intelligently decide
> which pages dynamically. This is related to skip scan.
>
> Attached is an example query that shows the problem. Right now the
> query needs to access a buffer containing an index page a total of 24
> times. It's actually accessing the same 2 pages 12 times. My draft
> patch only requires 2 buffer accesses -- because it "coalesces the
> array constants together" dynamically at run time. That is a little
> extreme, but it's certainly possible.
>
> BTW, this project is related to skip scan. It's part of the same
> family of techniques -- MDAM techniques. (I suppose that that's
> already true for ScalarArrayOpExpr execution by nbtree, but without
> dynamic behavior it's not nearly as valuable as it could be.)
>
> If executing ScalarArrayOpExprs was less inefficient in these cases
> then the planner could be a lot more aggressive about using them.
> Seems like these executor improvements might go well together with
> what you're doing in the planner. Note that I have to "set
> random_page_cost=0.1" to get the planner to use all of the quals from
> the query as index quals. It thinks (correctly) that the query plan is
> very inefficient. That happens to match reality right now, but the
> underlying reality could change significantly. Something to think
> about.
>
> --
> Peter Geoghegan
Thank you for your feedback, your work is also very interesting and
important, and I will be happy to review it. I learned something new
from your letter, thank you very much for that!
I analyzed the buffer consumption when I ran control regression tests
using my patch. diff shows me that there is no difference between the
number of buffer block scans without and using my patch, as far as I
have seen. (regression.diffs)
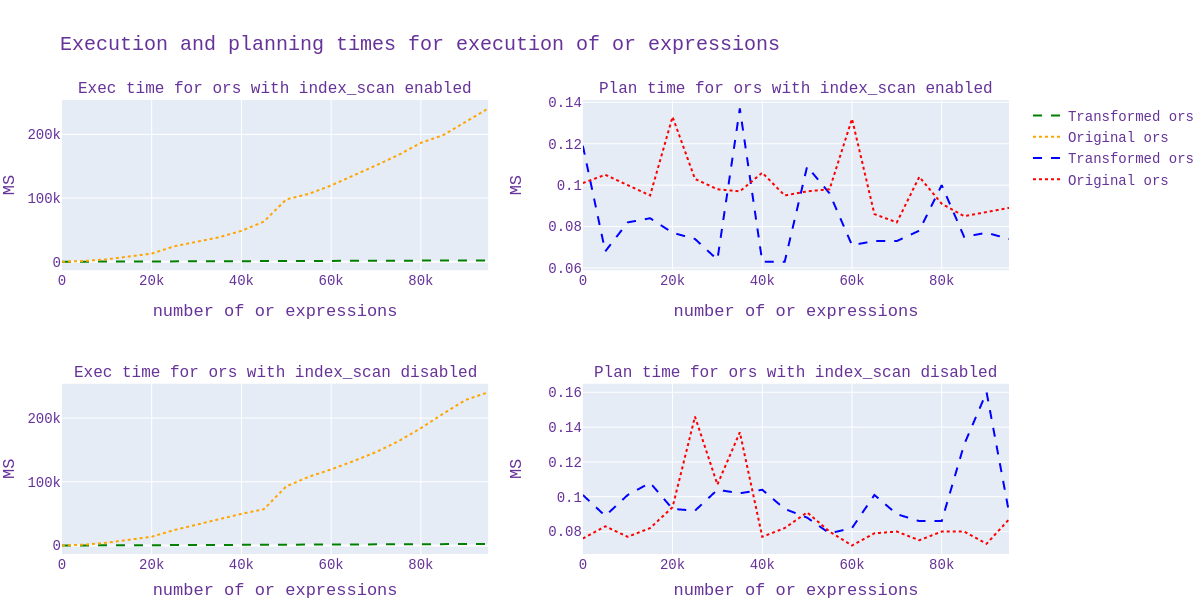
In addition, I analyzed the scheduling and duration of the execution
time of the source code and with my applied patch. I generated 20
billion data from pgbench and plotted the scheduling and execution time
depending on the number of "or" expressions.
By runtime, I noticed a clear acceleration for queries when using the
index, but I can't say the same when the index is disabled.
At first I turned it off in this way:
1)enable_seqscan='off'
2)enable_indexonlyscan='off'
enable_indexscan='off'
Unfortunately, it is not yet clear which constant needs to be set when
the transformation needs to be done, I will still study in detail. (the
graph for all this is presented in graph1.svg)
\\
--
Regards,
Alena Rybakina
| Attachment | Content-Type | Size |
|---|---|---|
| regression.diffs | text/plain | 13.1 KB |
| graph1.png | image/png | 109.5 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Amit Langote | 2023-06-27 13:22:33 | initial pruning in parallel append |
| Previous Message | Ants Aasma | 2023-06-27 11:49:48 | Re: ReadRecentBuffer() doesn't scale well |
{kind=link}