Re: shared-memory based stats collector
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Kyotaro HORIGUCHI <horiguchi(dot)kyotaro(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | alvherre(at)2ndquadrant(dot)com, andres(at)anarazel(dot)de, ah(at)cybertec(dot)at, magnus(at)hagander(dot)net, robertmhaas(at)gmail(dot)com, tgl(at)sss(dot)pgh(dot)pa(dot)us, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: shared-memory based stats collector |
| Date: | 2018-11-26 01:52:30 |
| Message-ID: | 6c079a69-feba-e47c-7b85-8a9ff31adef3@2ndquadrant.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
Unfortunately, the patch does not apply anymore - it seems it got broken
by the changes to signal handling and/or removal of magic OIDs :-(
I've done a review and testing when applied on top of 10074651e335.
Firstly, the testing - I was wondering if the patch has some performance
impact, so I've done some testing with a read-only workload on large
number of tables (1k, 10k and 100k) while concurrently selecting data
from pg_stat_* catalogs at the same time.
In one case both workloads were running against the same database, in
another there were two separate databases (and the selects from stat
catalogs were running against an "empty" database with no use tables).
In both cases there were 8 clients doing selects from the user tables,
and 4 clients accessing the pg_stat_* catalogs.
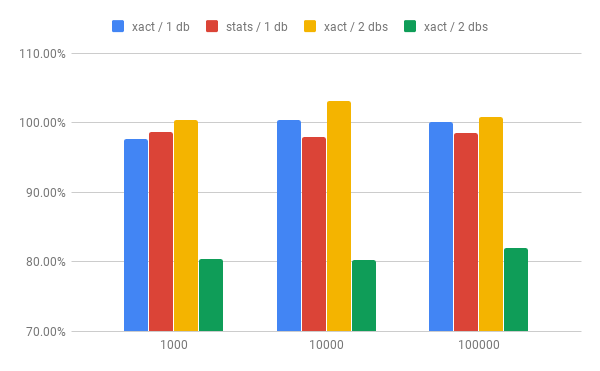
For the "single database" case the results looks like this (this is just
patched / master throughput):
# of tables xact stats
------------------------------
1000 97.71% 98.76%
10000 100.38% 97.97%
100000 100.10% 98.50%
xact is throughput of the user workload (select from the large number of
tables) and stats is throughput for selects from system catalogs.
So pretty much no difference - 2% is within noise on this machine.
On two separate databases the results are a bit more interesting:
# of tables xact stats
-------------------------------
1000 100.49% 80.38%
10000 103.18% 80.28%
100000 100.85% 81.95%
For the main workload there's pretty much no difference, but for selects
from the stats catalogs there's ~20% drop in throughput. In absolute
numbers this means drop from ~670tps to ~550tps. I haven't investigated
this, but I suppose this is due to dshash seqscan being more expensive
than reading the data from file.
I don't think any of this is an issue in practice, though. The important
thing is that there's no measurable impact on the regular workload.
Now, a couple of comments regarding individual parts of the patch.
0001-0003
---------
I do think 0001 - 0003 are ready, with some minor cosmetic issues:
1) I'd rephrase the last part of dshash_seq_init comment more like this:
* If consistent is set for dshash_seq_init, the all hash table
* partitions are locked in the requested mode (as determined by the
* exclusive flag), and the locks are held until the end of the scan.
* Otherwise the partition locks are acquired and released as needed
* during the scan (up to two partitions may be locked at the same time).
Maybe it should briefly explain what the consistency guarantees are (and
aren't), but considering we're not materially changing the existing
behavior probably is not really necessary.
2) I think the dshash_find_extended() signature should be more like
dshash_find(), i.e. just appending parameters instead of moving them
around unnecessarily. Perhaps we should add
Assert(nowait || !lock_acquired);
Using nowait=false with lock_acquired!=NULL does not seem sensible.
3) I suppose this comment in postmaster.c is just copy-paste:
-#define BACKEND_TYPE_ARCHIVER 0x0010 /* bgworker process */
+#define BACKEND_TYPE_ARCHIVER 0x0010 /* archiver process */
I wonder why wasn't archiver a regular auxiliary process already? It
seems like a fairly natural thing, so why not?
0004 (+0005 and 0007)
---------------------
This seems fine, but I have my doubts about two changes - removing of
stats_temp_directory and the IDLE_STATS_UPDATE_TIMEOUT thingy.
There's a couple of issues with the stats_temp_directory. Firstly, I
don't understand why it's spread over multiple parts of the patch. The
GUC is removed in 0004, the underlying variable is removed in 0005 and
then the docs are updated in 0007. If we really want to do this, it
should happen in a single patch.
But the main question is - do we really want to do that? I understand
this directory was meant for the stats data we're moving to shared
memory, so removing it seems natural. But clearly it's used by
pg_stat_statements - 0005 fixes that, of course, but I wonder if there
are other extensions using it to store files?
It's not just about how intensive I/O to those files is, but this also
means the files will now be included in backups / pg_rewind, and maybe
that's not really desirable?
Maybe it's fine but I'm not quite convinced about it ...
I'm not sure I understand what IDLE_STATS_UPDATE_TIMEOUT does. You've
described it as
This adds a new timeout IDLE_STATS_UPDATE_TIMEOUT. This works
similarly to IDLE_IN_TRANSACTIION_SESSION_TIMEOUT. It fires in
at most PGSTAT_STAT_MIN_INTERVAL(500)ms to clean up pending
statistics update.
but I'm not sure what pending updates do you mean? Aren't we updating
the stats at the end of each transaction? At least that's what we've
been doing before, so maybe this patch changes that?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 6.6 KB |
In response to
- Re: shared-memory based stats collector at 2018-11-13 15:35:27 from Tomas Vondra
Responses
- Re: shared-memory based stats collector at 2018-11-27 08:59:49 from Kyotaro HORIGUCHI
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tatsuro Yamada | 2018-11-26 02:05:56 | Tab completion for ALTER INDEX|TABLE ALTER COLUMN SET STATISTICS |
| Previous Message | Tom Lane | 2018-11-26 01:26:47 | Re: csv format for psql |