Parallel CREATE INDEX for GIN indexes
| From: | Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
|---|---|
| To: | PostgreSQL Hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Parallel CREATE INDEX for GIN indexes |
| Date: | 2024-05-02 15:19:03 |
| Message-ID: | 6ab4003f-a8b8-4d75-a67f-f25ad98582dc@enterprisedb.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
In PG17 we shall have parallel CREATE INDEX for BRIN indexes, and back
when working on that I was thinking how difficult would it be to do
something similar to do that for other index types, like GIN. I even had
that on my list of ideas to pitch to potential contributors, as I was
fairly sure it's doable and reasonably isolated / well-defined.
However, I was not aware of any takers, so a couple days ago on a slow
weekend I took a stab at it. And yes, it's doable - attached is a fairly
complete, tested and polished version of the feature, I think. It turned
out to be a bit more complex than I expected, for reasons that I'll get
into when discussing the patches.
First, let's talk about the benefits - how much faster is that than the
single-process build we have for GIN indexes? I do have a table with the
archive of all our mailing lists - it's ~1.5M messages, table is ~21GB
(raw dump is about 28GB). This does include simple text data (message
body), JSONB (headers) and tsvector (full-text on message body).
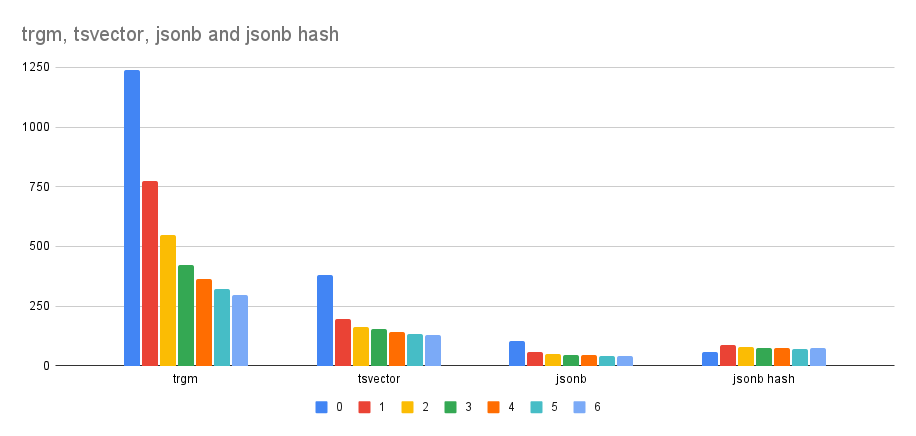
If I do CREATE index with different number of workers (0 means serial
build), I get this timings (in seconds):
workers trgm tsvector jsonb jsonb (hash)
-----------------------------------------------------
0 1240 378 104 57
1 773 196 59 85
2 548 163 51 78
3 423 153 45 75
4 362 142 43 75
5 323 134 40 70
6 295 130 39 73
Perhaps an easier to understand result is this table with relative
timing compared to serial build:
workers trgm tsvector jsonb jsonb (hash)
-----------------------------------------------------
1 62% 52% 57% 149%
2 44% 43% 49% 136%
3 34% 40% 43% 132%
4 29% 38% 41% 131%
5 26% 35% 39% 123%
6 24% 34% 38% 129%
This shows the benefits are pretty nice, depending on the opclass. For
most indexes it's maybe ~3-4x faster, which is nice, and I don't think
it's possible to do much better - the actual index inserts can happen
from a single process only, which is the main limit.
For some of the opclasses it can regress (like the jsonb_path_ops). I
don't think that's a major issue. Or more precisely, I'm not surprised
by it. It'd be nice to be able to disable the parallel builds in these
cases somehow, but I haven't thought about that.
I do plan to do some tests with btree_gin, but I don't expect that to
behave significantly differently.
There are small variations in the index size, when built in the serial
way and the parallel way. It's generally within ~5-10%, and I believe
it's due to the serial build adding the TIDs incrementally, while the
build adds them in much larger chunks (possibly even in one chunk with
all the TIDs for the key). I believe the same size variation can happen
if the index gets built in a different way, e.g. by inserting the data
in a different order, etc. I did a number of tests to check if the index
produces the correct results, and I haven't found any issues. So I think
this is OK, and neither a problem nor an advantage of the patch.
Now, let's talk about the code - the series has 7 patches, with 6
non-trivial parts doing changes in focused and easier to understand
pieces (I hope so).
1) v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch
This is the initial feature, adding the "basic" version, implemented as
pretty much 1:1 copy of the BRIN parallel build and minimal changes to
make it work for GIN (mostly about how to store intermediate results).
The basic idea is that the workers do the regular build, but instead of
flushing the data into the index after hitting the memory limit, it gets
written into a shared tuplesort and sorted by the index key. And the
leader then reads this sorted data, accumulates the TID for a given key
and inserts that into the index in one go.
2) v20240502-0002-Use-mergesort-in-the-leader-process.patch
The approach implemented by 0001 works, but there's a little bit of
issue - if there are many distinct keys (e.g. for trigrams that can
happen very easily), the workers will hit the memory limit with only
very short TID lists for most keys. For serial build that means merging
the data into a lot of random places, and in parallel build it means the
leader will have to merge a lot of tiny lists from many sorted rows.
Which can be quite annoying and expensive, because the leader does so
using qsort() in the serial part. It'd be better to ensure most of the
sorting happens in the workers, and the leader can do a mergesort. But
the mergesort must not happen too often - merging many small lists is
not cheaper than a single qsort (especially when the lists overlap).
So this patch changes the workers to process the data in two phases. The
first works as before, but the data is flushed into a local tuplesort.
And then each workers sorts the results it produced, and combines them
into results with much larger TID lists, and those results are written
to the shared tuplesort. So the leader only gets very few lists to
combine for a given key - usually just one list per worker.
3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch
In 0002 the workers still do an explicit qsort() on the TID list before
writing the data into the shared tuplesort. But we can do better - the
workers can do a merge sort too. To help with this, we add the first TID
to the tuplesort tuple, and sort by that too - it helps the workers to
process the data in an order that allows simple concatenation instead of
the full mergesort.
Note: There's a non-obvious issue due to parallel scans always being
"sync scans", which may lead to very "wide" TID ranges when the scan
wraps around. More about that later.
4) v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch
The parallel build passes data between processes using temporary files,
which means it may need significant amount of disk space. For BRIN this
was not a major concern, because the summaries tend to be pretty small.
But for GIN that's not the case, and the two-phase processing introduced
by 0002 make it worse, because the worker essentially creates another
copy of the intermediate data. It does not need to copy the key, so
maybe it's not exactly 2x the space requirement, but in the worst case
it's not far from that.
But there's a simple way how to improve this - the TID lists tend to be
very compressible, and GIN already implements a very light-weight TID
compression, so this patch does just that - when building the tuple to
be written into the tuplesort, we just compress the TIDs.
5) v20240502-0005-Collect-and-print-compression-stats.patch
This patch simply collects some statistics about the compression, to
show how much it reduces the amounts of data in the various phases. The
data I've seen so far usually show ~75% compression in the first phase,
and ~30% compression in the second phase.
That is, in the first phase we save ~25% of space, in the second phase
we save ~70% of space. An example of the log messages from this patch,
for one worker (of two) in the trigram phase says:
LOG: _gin_parallel_scan_and_build raw 10158870494 compressed 7519211584
ratio 74.02%
LOG: _gin_process_worker_data raw 4593563782 compressed 1314800758
ratio 28.62%
Put differently, a single-phase version without compression (as in 0001)
would need ~10GB of disk space per worker. With compression, we need
only about ~8.8GB for both phases (or ~7.5GB for the first phase alone).
I do think these numbers look pretty good. The numbers are different for
other opclasses (trigrams are rather extreme in how much space they
need), but the overall behavior is the same.
6) v20240502-0006-Enforce-memory-limit-when-combining-tuples.patch
Until this part, there's no limit on memory used by combining results
for a single index key - it'll simply use as much memory as needed to
combine all the TID lists. Which may not be a huge issue because each
TID is only 6B, and we can accumulate a lot of those in a couple MB. And
a parallel CREATE INDEX usually runs with a fairly significant values of
maintenance_work_mem (in fact it requires it to even allow parallel).
But still, there should be some memory limit.
It however is not as simple as dumping current state into the index,
because the TID lists produced by the workers may overlap, so the tail
of the list may still receive TIDs from some future TID list. And that's
a problem because ginEntryInsert() expects to receive TIDs in order, and
if that's not the case it may fail with "could not split GIN page".
But we already have the first TID for each sort tuple (and we consider
it when sorting the data), and this is useful for deducing how far we
can flush the data, and keep just the minimal part of the TID list that
may change by merging.
So this patch implements that - it introduces the concept of "freezing"
the head of the TID list up to "first TID" from the next tuple, and uses
that to write data into index if needed because of memory limit.
We don't want to do that too often, so it only happens if we hit the
memory limit and there's at least a certain number (1024) of TIDs.
7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch
There's one more efficiency problem - the parallel scans are required to
be synchronized, i.e. the scan may start half-way through the table, and
then wrap around. Which however means the TID list will have a very wide
range of TID values, essentially the min and max of for the key.
Without 0006 this would cause frequent failures of the index build, with
the error I already mentioned:
ERROR: could not split GIN page; all old items didn't fit
tracking the "safe" TID horizon addresses that. But there's still an
issue with efficiency - having such a wide TID list forces the mergesort
to actually walk the lists, because this wide list overlaps with every
other list produced by the worker. And that's much more expensive than
just simply concatenating them, which is what happens without the wrap
around (because in that case the worker produces non-overlapping lists).
One way to fix this would be to allow parallel scans to not be sync
scans, but that seems fairly tricky and I'm not sure if that can be
done. The BRIN parallel build had a similar issue, and it was just
simpler to deal with this in the build code.
So 0007 does something similar - it tracks if the TID value goes
backward in the callback, and if it does it dumps the state into the
tuplesort before processing the first tuple from the beginning of the
table. Which means we end up with two separate "narrow" TID list, not
one very wide one.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 17.2 KB |

|
image/png | 23.7 KB |
| v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch | text/x-patch | 56.2 KB |
| v20240502-0002-Use-mergesort-in-the-leader-process.patch | text/x-patch | 9.6 KB |
| v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch | text/x-patch | 11.1 KB |
| v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch | text/x-patch | 8.0 KB |
| v20240502-0005-Collect-and-print-compression-stats.patch | text/x-patch | 5.1 KB |
| v20240502-0006-Enforce-memory-limit-when-combining-tuples.patch | text/x-patch | 14.8 KB |
| v20240502-0007-Detect-wrap-around-in-parallel-callback.patch | text/x-patch | 5.7 KB |
Responses
- Re: Parallel CREATE INDEX for GIN indexes at 2024-05-02 17:12:27 from Matthias van de Meent
- Re: Parallel CREATE INDEX for GIN indexes at 2024-05-09 10:14:40 from Andy Fan
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David G. Johnston | 2024-05-02 15:23:44 | Re: Document NULL |
| Previous Message | Peter Geoghegan | 2024-05-02 15:05:25 | Re: Limit index pages visited in planner's get_actual_variable_range |