Re: WIP: bloom filter in Hash Joins with batches
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: WIP: bloom filter in Hash Joins with batches |
| Date: | 2016-01-09 19:02:35 |
| Message-ID: | 5691594B.4070209@2ndquadrant.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
attached are results for some basic performance evaluation of the patch
(and also scripts used for the evaluation). I've used a simple join of
two tables ("fact" and "dim"), with three different dataset sizes.
CREATE TABLE dim (id INT, r INT, val TEXT);
CREATE TABLE fact (id INT, val TEXT);
-- 1M rows into "dim"
INSERT INTO dim
SELECT i, mod(i,100), md5(i::text) FROM generate_series(1,1000000) s(i);
-- 10M rows into "fact"
INSERT INTO fact
SELECT mod(i,1000000)+1, md5((mod(i,1000000)+1)::text)
FROM generate_series(1,10000000) s(i);
Which means the "dim.r" column has 100 different values (0-99) with
uniform distribution. So e.g. "WHERE r < 15" matches 15%.
There are three dataset sizes:
1) small: dim 1M rows (73MB), fact 10M rows (650MB)
2) medium: dim: 10M rows (730MB), fact 100M rows (6.5GB)
3) large: dim: 5M rows (365MB), fact 250M rows (16GB)
The machine has 8GB of RAM, so "small" easily fits into RAM, "medium" is
just at the border, and "large" is clearly over (especially when batching).
For each dataset size there are two queries - one with inner and one
with outer join, with a filter on the smaller one ("dim") determining
the "selectivity".
-- inner join
SELECT COUNT(dim.val), COUNT(fact.val)
FROM fact JOIN dim ON (fact.id = dim.id) WHERE r < $1
-- outer join
SELECT COUNT(dim.val), COUNT(fact.val)
FROM fact LEFT JOIN (SELECT * FROM dim WHERE r < $1) dim
ON (fact.id = dim.id)
Those queries were executed with various work_mem sizes (to either use
no batching or different number of batches), and also with different
filter values (to filter to 10%, 20%, 30%, ...., 100% of data).
After collecting data both on master and with all the patches applied,
I've computed the speedup factor as
(time with patches) / (time on master)
and plotted that as a pivot tables with heat map. Values <1.0 (red) mean
"bloom filter made the query faster" while values > 1.0 (blue) means it
slowed the query down.
Let's quickly skim through the results for each dataset size. The
attached charts only show results for the "inner" queries, but the
results for "outer" queries are pretty much exactly the same.
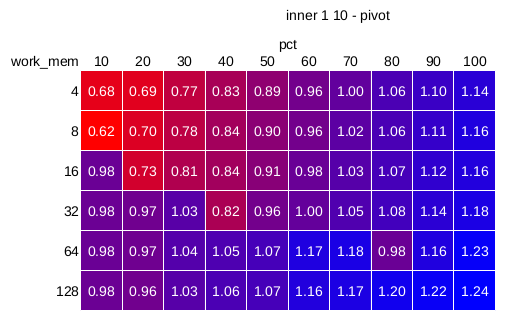
1) small (hash-joins-bloom-1-10.png)
------------------------------------
There's a clear speedup as long as the hash join requires batching and
the selectivity is below 50-60%. In the best case (10% selectivity,
small work_mem and thus multiple batches) we save up to ~30% of time.
Once we get to non-batching mode, the bloom filter is ineffective no
matter the selectivity. I assume this is because for the small
selectivities (e.g. 10%) it's simply cheaper to check the hash table,
which is small and likely fits into L3 on the CPU (which is ~6MB on the
i5-2500 CPU in the system).
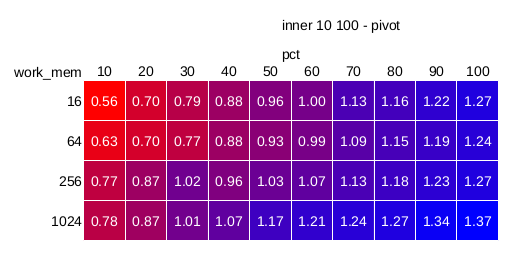
2) medium (hash-joins-bloom-10-100.png)
---------------------------------------
The results are similar to the "small" results, except that the speedup
is somewhat larger (up to 40%), and there's no sudden jump when the
queries stop batching (work_mem=1GB is enough to run the query in a
single batch even with 100% selectivity). The "break-even" selectivity
is again somewhere around 50% (a bit lower in non-batching mode).
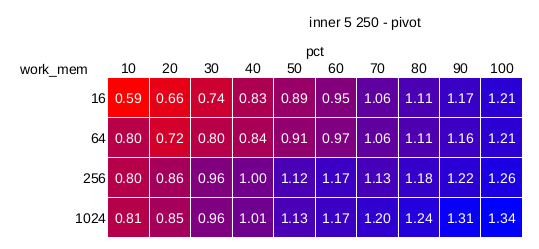
3) large (hash-joins-bloom-5-250.png)
-------------------------------------
Pretty much the same as "medium".
So, this seems to bring reasonable speedup, as long as the selectivity
is below 50%, and the data set is sufficiently large.
It's however clear that the patch won't work without some sort of
selectivity estimation - either at planning time or optimization time
(or both). I've speculated about how to do that, but the current patches
don't implement any of that yet and any ideas are welcome.
Another open question is sizing the bloom filter in the multi-batch
case, which turns out to be quite tricky. What the patch does right now
is estimating the number of distinct values to store in the filter based
on the first batch (the other hashjoin patch in this CF makes this
possible). That is, there's a hyperloglog counter that gives us (very
accurate) ndistinct estimate for the first batch, and then we do (nbatch
* ndistinct), to estimate the ndistinct values in the whole data set.
That estimate is of course rather naive, and often produces too high -
for example we might have already seen all the distinct values in the
first batch. So the result is a bloom filter much larger than necessary.
Not sure how to fix this :-(
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 29.1 KB |
|
image/png | 29.3 KB |
|
image/png | 41.6 KB |
| hash-joins-bloom.ods | application/vnd.oasis.opendocument.spreadsheet | 51.3 KB |
| hash-scripts.tgz | application/x-compressed-tar | 5.5 KB |
In response to
- Re: WIP: bloom filter in Hash Joins with batches at 2015-12-24 13:51:15 from Simon Riggs
Responses
- Re: WIP: bloom filter in Hash Joins with batches at 2016-01-10 00:08:03 from Peter Geoghegan
- Re: WIP: bloom filter in Hash Joins with batches at 2016-01-10 04:11:01 from Peter Geoghegan
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tomas Vondra | 2016-01-09 19:46:23 | Re: PATCH: Extending the HyperLogLog API a bit |
| Previous Message | Steve Singer | 2016-01-09 18:30:45 | Re: pglogical - logical replication contrib module |