Re: WIP: BRIN multi-range indexes
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | Mark Dilger <hornschnorter(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, pgsql-hackers(at)postgreSQL(dot)org |
| Subject: | Re: WIP: BRIN multi-range indexes |
| Date: | 2018-04-03 19:50:55 |
| Message-ID: | 4b0f4205-57b2-77d4-d500-510cbad25d7b@2ndquadrant.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
attached is updated and slightly improved version of the two BRIN
opclasses (bloom and multi-range minmax). Given the lack of reviews I
think it's likely to get bumped to 2018-09, which I guess is OK - it
surely needs more feedback regarding some decisions. So let me share
some thoughts about those, before I forget all of it, and some test
results showing the pros/cons of those indexes.
1) index parameters
The main improvement of this version is an introduction of a couple of
BRIN index parameters, next to pages_per_range and autosummarize.
a) n_distinct_per_range - used to size Bloom index
b) false_positive_rate - used to size Bloom index
c) values_per_range - number of values in the minmax-multi summary
Until now those parameters were pretty much hard-coded, this allows easy
customization depending on the data set. There are some basic rules to
to clamp the values (e.g. not to allow ndistinct to be less than 128 or
more than MaxHeapTuplesPerPage * page_per_range), but that's about it.
I'm sure we could devise more elaborate heuristics (e.g. when building
index on an existing table, we could inspect table statistics first),
but the patch does not do that.
One disadvantage is that those parameters are per-index. It's possible
to define multi-column BRIN index, possibly with different opclasses:
CREATE INDEX ON t USING brin (a int4_bloom_ops,
b int8_bloom_ops,
c int4_minmax_multi_ops,
d int8_minmax_multi_ops)
WITH (false_positive_rate = 0.01,
n_distinct_per_range = 1024,
values_per_range = 32);
in which case the parameters apply to all columns (with the relevant
opclass type). So for example false_positive_rate applies to both "a"
and "b".
This is somewhat unfortunate, but I don't think it's worth inventing
more complex solution. If you need to specify different parameters, you
can simply build separate indexes, and it's more practical anyway
because all the summaries must fit on the same index page which limits
the per-column space. So people are more likely to define single-column
bloom indexes anyway.
There's a room for improvement when it comes to validating the
parameters. For example, it's possible to specify parameters that would
produce bloom filters larger than 8kB, which may lead with over-sized
index rows later. For minmax-multi indexes this should be relatively
safe (maximum number of values is 256, which is low enough for all
fixed-length types). Of course, varlena columns can break it, but we
can't really validate those anyway.
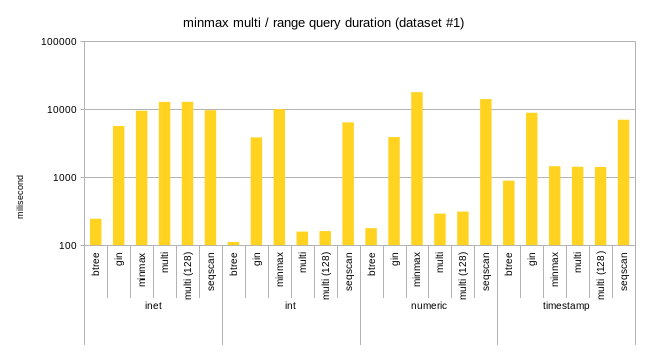
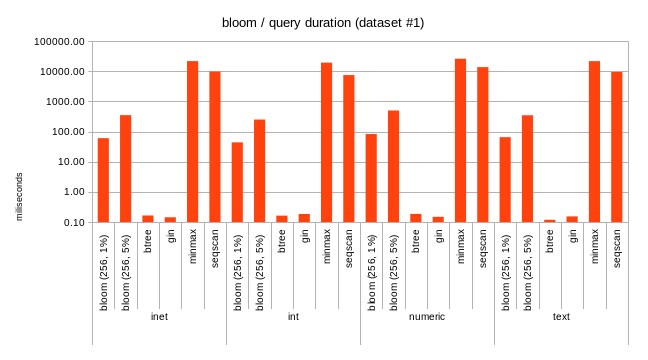
2) test results
The attached spreadsheet shows results comparing these opclasses to
existing BRIN indexes, and also to BTREE/GIN. Clearly, the dataset were
picked to show advantages of those approaches, e.g. on data sets where
regular minmax fails to deliver any benefits.
Overall I think it looks nice - the indexes are larger than minmax
(expected, the summaries are larger), but still orders of magnitude
smaller than BTREE or even GIN. For bloom the build time is comparable
to minmax, for minmax-multi it's somewhat slower - again, I'm sure
there's room for improvements.
For query performance, it's clearly better than plain minmax (but well,
the datasets were constructed to demonstrate that, so no surprise here).
One interesting thing I haven't realized initially is the relationship
between false positive rate for Bloom indexes, and the fraction of table
scanned by a query on average. Essentially, a bloom index with 1% false
positive rate is expected to scan about 1% of table on average. That
pretty accurately determines the performance of bloom indexes.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| 0001-Pass-all-keys-to-BRIN-consistent-function-a-20180403.patch.gz | application/gzip | 5.4 KB |
| 0002-Move-IS-NOT-NULL-checks-to-bringetbitmap-20180403.patch.gz | application/gzip | 2.9 KB |
| 0003-BRIN-bloom-indexes-20180403.patch.gz | application/gzip | 20.0 KB |
| 0004-BRIN-multi-range-minmax-indexes-20180403.patch.gz | application/gzip | 29.4 KB |
| brin-results.ods | application/vnd.oasis.opendocument.spreadsheet | 65.9 KB |
|
image/png | 12.6 KB |
|
image/png | 14.9 KB |
| bloom.sql | application/sql | 15.2 KB |
| minmax-multi.sql | application/sql | 24.9 KB |
In response to
- Re: WIP: BRIN multi-range indexes at 2018-03-21 00:07:22 from Tomas Vondra
Responses
- Re: WIP: BRIN multi-range indexes at 2018-06-24 02:01:47 from Tomas Vondra
- Re: WIP: BRIN multi-range indexes at 2019-02-23 22:23:22 from Tomas Vondra
- Re: WIP: BRIN multi-range indexes at 2019-03-02 09:00:10 from Alexander Korotkov
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | TipTop Labs | 2018-04-03 20:13:05 | Re: BUG #14999: pg_rewind corrupts control file global/pg_control |
| Previous Message | Justin Pryzby | 2018-04-03 19:46:13 | open/lseek overhead with many partitions (including with "faster partitioning pruning") |