Re: POC, WIP: OR-clause support for indexes
| From: | Alena Rybakina <lena(dot)ribackina(at)yandex(dot)ru> |
|---|---|
| To: | Ranier Vilela <ranier(dot)vf(at)gmail(dot)com>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Cc: | Pg Hackers <pgsql-hackers(at)postgresql(dot)org>, Marcos Pegoraro <marcos(at)f10(dot)com(dot)br> |
| Subject: | Re: POC, WIP: OR-clause support for indexes |
| Date: | 2023-06-29 05:50:21 |
| Message-ID: | 2a359f41-85f4-6846-cf1b-1e3855b29aa7@yandex.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi!
On 29.06.2023 04:36, Ranier Vilela wrote:
>
> I don't want to be rude, but this doesn't seem very helpful.
>
> Sorry, It was not my intention to cause interruptions.
>
>
> - You made some changes, but you don't even attempt to explain
> what you
> changed or why you changed it.
>
> 1. Reduce scope
> 2. Eliminate unnecessary variables
> 3. Eliminate unnecessary expressions
>
>
> - You haven't even tried to compile the code, nor tested it. If it
> happens to compile, wow could others even know it actually behaves the
> way you wanted?
>
Sorry I didn't answer right away. I will try not to do this in the
future thank you for your participation and help.
Yes, the scope of this patch may be small, but I am sure that it will
solve the worst case of memory consumption with large numbers of "or"
expressions or reduce execution and planning time. As I have already
said, I conducted a launch on a database with 20 billion data generated
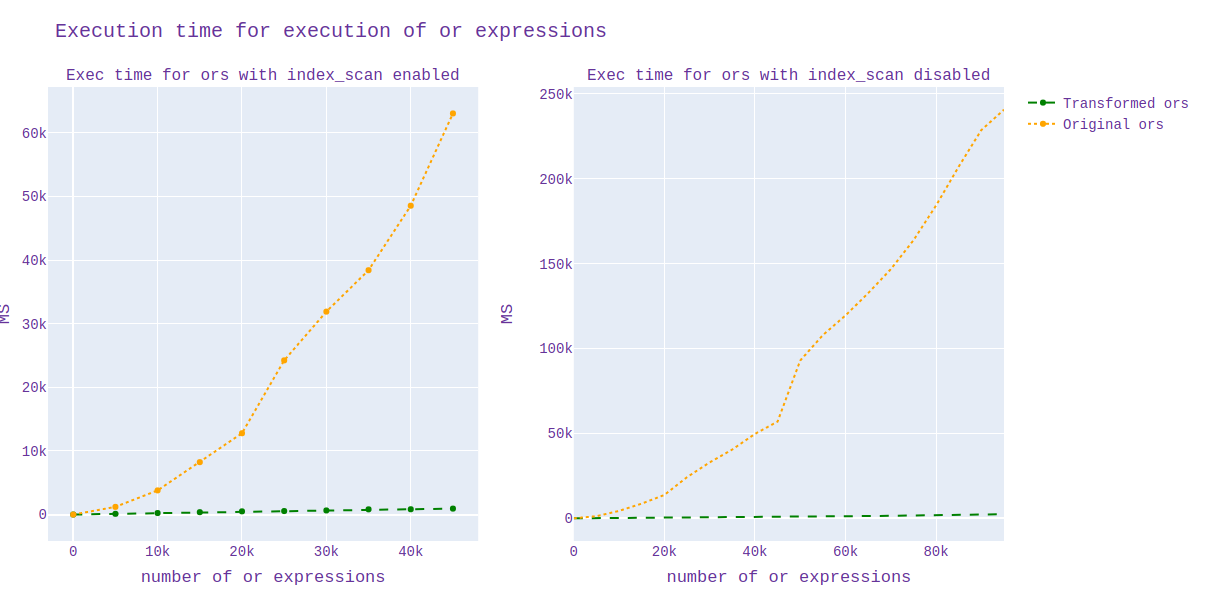
using a benchmark. Unfortunately, at that time I sent a not quite
correct picture: the execution time, not the planning time, increases
with the number of "or" expressions (execution_time.png). x is the
number of or expressions, y is the execution/scheduling time.
I also throw memory consumption at 50,000 "or" expressions collected by
HeapTrack (where memory consumption was recorded already at the
initialization stage of the 1.27GB pic3.png). I think such a
transformation will allow just the same to avoid such a worst case,
since in comparison with ANY memory is much less and takes little time.
SELECT FORMAT('prepare x %s AS SELECT * FROM pgbench_accounts a WHERE %s',
'(' || string_agg('int',',') ||')',
string_agg(FORMAT('aid = $%s', g.id),' or ')
) AS cmd
FROM generate_series(1, 50000) AS g(id)
\gexec
SELECT FORMAT('execute x %s;','(' || string_agg(g.id::text,',') ||')') AS cmd
FROM generate_series(1, 50000) AS g(id)
\gexec
I tried to add a transformation at the path formation stage before we
form indexes (set_plain_rel_pathlist function) and at the stage when we
have preprocessing of "or" expressions (getting rid of duplicates or
useless conditions), but everywhere there was a problem of incorrect
selectivity estimation.
CREATE TABLE tenk1 (unique1int, unique2int, tenint, hundredint);
insert into tenk1 SELECT x,x,x,x FROM generate_series(1,50000) as x;
CREATE INDEX a_idx1 ON tenk1(unique1);
CREATE INDEX a_idx2 ON tenk1(unique2);
CREATE INDEX a_hundred ON tenk1(hundred);
postgres=# explain analyze
select * from tenk1 a join tenk1 b on
((a.unique2 = 3 or a.unique2 = 7)) or (a.unique1 = 1);
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.00..140632434.50 rows=11250150000 width=32) (actual time=0.077..373.279 rows=1350000 loops=1)
-> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.037..13.941 rows=150000 loops=1)
-> Materialize (cost=0.00..3436.01 rows=75001 width=16) (actual time=0.000..0.001 rows=9 loops=150000)
-> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=75001 width=16) (actual time=0.027..59.174 rows=9 loops=1)
Filter: ((unique2 = ANY (ARRAY[3, 7])) OR (unique1 = 1))
Rows Removed by Filter: 149991
Planning Time: 0.438 ms
Execution Time: 407.144 ms
(8 rows)
Only by converting the expression at this stage, we do not encounter
this problem.
postgres=# set enable_bitmapscan ='off';
SET
postgres=# explain analyze
select * from tenk1 a join tenk1 b on
a.unique2 = 3 or a.unique2 = 7 or a.unique1 = 1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.00..22247.02 rows=1350000 width=32) (actual time=0.094..373.627 rows=1350000 loops=1)
-> Seq Scan on tenk1 b (cost=0.00..2311.00 rows=150000 width=16) (actual time=0.051..14.667 rows=150000 loops=1)
-> Materialize (cost=0.00..3061.05 rows=9 width=16) (actual time=0.000..0.001 rows=9 loops=150000)
-> Seq Scan on tenk1 a (cost=0.00..3061.00 rows=9 width=16) (actual time=0.026..42.389 rows=9 loops=1)
Filter: ((unique2 = ANY ('{3,7}'::integer[])) OR (unique1 = 1))
Rows Removed by Filter: 149991
Planning Time: 0.414 ms
Execution Time: 409.154 ms
(8 rows)
I compiled my original patch and there were no problems with regression
tests. The only time there was a problem when I set the
const_transform_or_limit variable to 0 (I have 15), as you have in the
patch. To be honest, diff appears there because you had a different
plan, specifically the expressions "or" are replaced by ANY (see
regression.diffs).
Unfortunately, your patch version did not apply immediately, I did not
understand the reasons, I applied it manually.
At the moment, I'm not sure that the constant is the right number for
applying transformations, so I'm in search of it, to be honest. I will
post my observations on this issue later. If you don't mind, I'll leave
the constant equal to 15 for now.
Sorry, I don't understand well enough what is meant by points "Eliminate
unnecessary variables" and "Eliminate unnecessary expressions". Can you
explain in more detail?
Regarding the patch, there was a Warning at the compilation stage.
In file included from ../../../src/include/nodes/bitmapset.h:21,
from ../../../src/include/nodes/parsenodes.h:26,
from ../../../src/include/catalog/objectaddress.h:17,
from ../../../src/include/catalog/pg_aggregate.h:24,
from parse_expr.c:18:
parse_expr.c: In function ‘transformBoolExprOr’:
../../../src/include/nodes/nodes.h:133:66: warning: ‘expr’ is used uninitialized [-Wuninitialized]
133 | #define nodeTag(nodeptr) (((const Node*)(nodeptr))->type)
| ^~
parse_expr.c:116:29: note: ‘expr’ was declared here
116 | BoolExpr *expr;
| ^~~~
I couldn't figure out how to fix it and went back to my original
version. To be honest, I don't think anything needs to be changed here.
Unfortunately, I didn't understand the reasons why, with the available
or expressions, you don't even try to convert to ANY by calling
transformBoolExpr, as I saw. I went back to my version.
I think it's worth checking whether the or_statement variable is positive.
I think it's worth leaving the use of the or_statement variable in its
original form.
switch (expr->boolop)
{
case AND_EXPR:
opname = "AND";
break;
case OR_EXPR:
opname = "OR";
or_statement = true;
break;
case NOT_EXPR:
opname = "NOT";
break;
default:
elog(ERROR, "unrecognized boolop: %d", (int) expr->boolop);
opname = NULL; /* keep compiler quiet */
break;
}
if (!or_statement || list_length(expr->args) < const_transform_or_limit)
return transformBoolExpr(pstate, (BoolExpr *)expr_orig);
The current version of the patch also works and all tests pass.
--
Regards,
Alena Rybakina
Postgres Professional
| Attachment | Content-Type | Size |
|---|---|---|
| regression.diffs | text/plain | 11.3 KB |
| 0001-Replace-clause-X-N1-OR-X-N2-.-with-X-ANY-N1-N2-on.patch | text/x-patch | 10.6 KB |
| pic3.png | image/png | 106.0 KB |
|
image/png | 53.6 KB |
{kind=link}
In response to
- Re: POC, WIP: OR-clause support for indexes at 2023-06-29 01:36:48 from Ranier Vilela
Responses
- Re: POC, WIP: OR-clause support for indexes at 2023-06-29 12:25:20 from Ranier Vilela
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Alena Rybakina | 2023-06-29 06:10:42 | Re: POC, WIP: OR-clause support for indexes |
| Previous Message | Nathan Bossart | 2023-06-29 05:24:09 | Re: harmonize password reuse in vacuumdb, clusterdb, and reindexdb |