| From: | Jehan-Guillaume de Rorthais <jgdr(at)dalibo(dot)com> |
|---|---|
| To: | pgsql-hackers(at)lists(dot)postgresql(dot)org |
| Subject: | Memory leak from ExecutorState context? |
| Date: | 2023-02-28 18:06:43 |
| Message-ID: | 20230228190643.1e368315@karst |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello all,
A customer is facing out of memory query which looks similar to this situation:
This PostgreSQL version is 11.18. Some settings:
* shared_buffers: 8GB
* work_mem: 64MB
* effective_cache_size: 24GB
* random/seq_page_cost are by default
* physical memory: 32GB
The query is really large and actually update kind of a materialized view.
The customer records the plans of this query on a regular basis. The explain
analyze of this query before running out of memory was:
https://explain.depesz.com/s/sGOH
The customer is aware he should rewrite this query to optimize it, but it's a
long time process he can not start immediately. To make it run in the meantime,
he actually removed the top CTE to a dedicated table. According to their
experience, it's not the first time they had to split a query this way to make
it work.
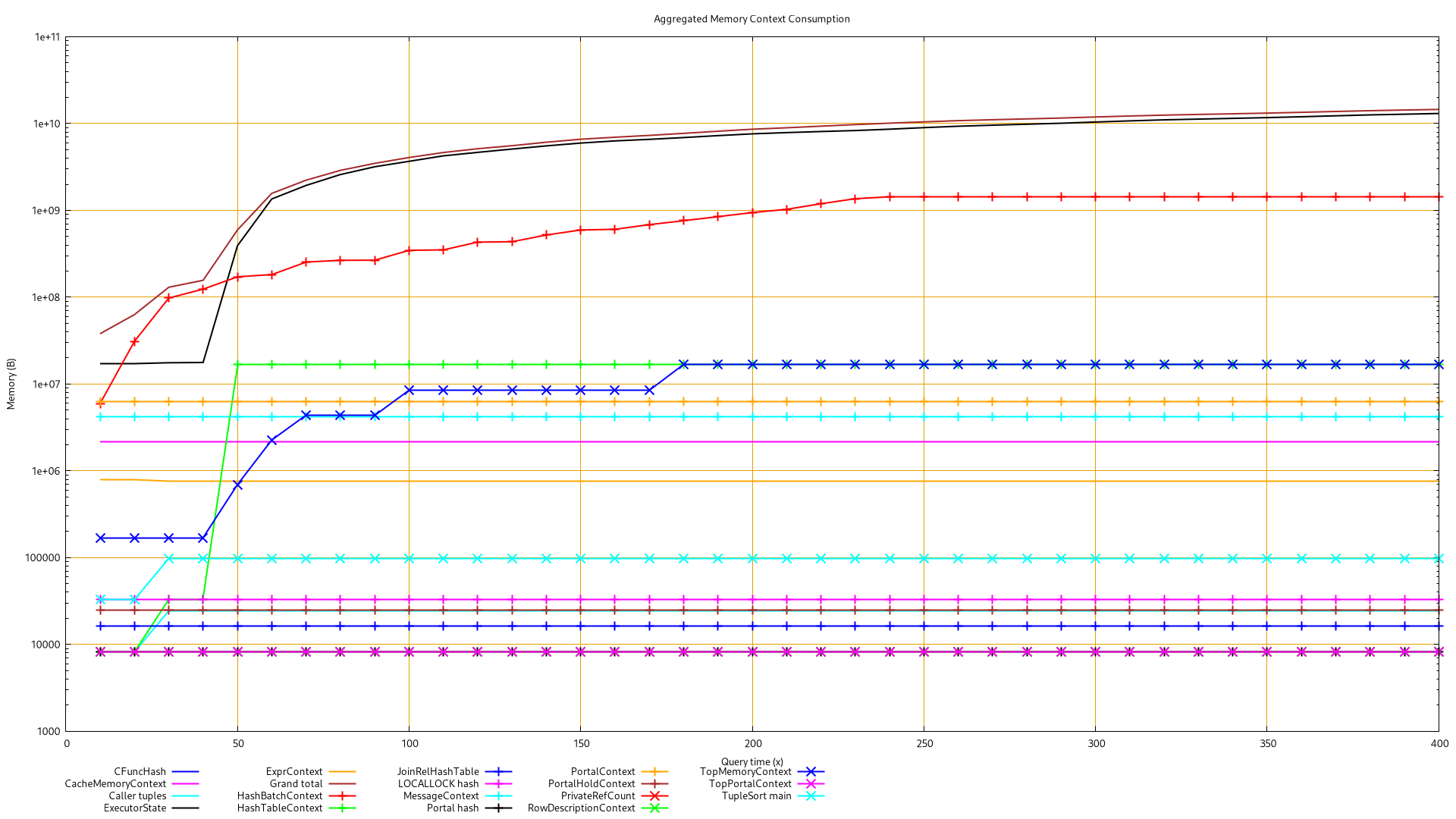
I've been able to run this query on a standby myself. I've "call
MemoryContextStats(TopMemoryContext)" every 10s on a run, see the data parsed
(best view with "less -S") and the graph associated with it in attachment. It
shows:
* HashBatchContext goes up to 1441MB after 240s then stay flat until the end
(400s as the last record)
* ALL other context are stable before 240s, but ExecutorState
* ExecutorState keeps rising up to 13GB with no interruption until the memory
exhaustion
I did another run with interactive gdb session (see the messy log session in
attachment, for what it worth). Looking at some backtraces during the memory
inflation close to the end of the query, all of them were having these frames in
common:
[...]
#6 0x0000000000621ffc in ExecHashJoinImpl (parallel=false, pstate=0x31a3378)
at nodeHashjoin.c:398 [...]
...which is not really helpful but at least, it seems to come from a hash join
node or some other hash related code. See the gdb session log for more details.
After the out of mem, pmap of this process shows:
430: postgres: postgres <dbname> [local] EXPLAIN
Address Kbytes RSS Dirty Mode Mapping
[...]
0000000002c5e000 13719620 8062376 8062376 rw--- [ anon ]
[...]
Is it usual a backend is requesting such large memory size (13 GB) and
actually use less of 60% of it (7.7GB of RSS)?
Sadly, the database is 1.5TB large and I can not test on a newer major version.
I did not try to check how large would be the required data set to reproduce
this, but it moves 10s of million of rows from multiple tables anyway...
Any idea? How could I help to have a better idea if a leak is actually
occurring and where exactly?
Regards,
| Attachment | Content-Type | Size |
|---|---|---|
| evo-context-tue.png | image/png | 95.0 KB |
| gdb.txt.gz | application/gzip | 23.5 KB |
| postgresql-Tue.contexts.gz | application/gzip | 1.5 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Justin Pryzby | 2023-02-28 18:25:08 | Re: Memory leak from ExecutorState context? |
| Previous Message | Tomas Vondra | 2023-02-28 18:01:41 | Re: logical decoding and replication of sequences, take 2 |
{kind=link}