General purpose hashing func in pgbench
| From: | Ildar Musin <i(dot)musin(at)postgrespro(dot)ru> |
|---|---|
| To: | pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Fabien COELHO <coelho(at)cri(dot)ensmp(dot)fr> |
| Subject: | General purpose hashing func in pgbench |
| Date: | 2017-12-20 05:58:18 |
| Message-ID: | 0e8bd39e-dfcd-2879-f88f-272799ad7ef2@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi hackers,
Following up the recent discussion on zipfian distribution I was trying
to reproduce some YCSB-like workloads. As this paper [1] describes, YCSB
uses zipfian distribution to generate keys in order simulate intensive
load on small number of records as it happens in real world applications
(e.g. blogs). One problem is that most popular records keys are
clustered together. To scatter them across the keyspace authors use
hashing, the FNV-1a hash function in particular [2].
I've read Fabien Coelho's thread on additional operators and functions.
Generally it could be possible to implement some basic hashing
algorithms right in a pgbench script using just bitwise and arithmetic
operators. But should we probably provide users with some general
purpose hash function?
The attached patch introduces hash() function which implements FNV-1a as
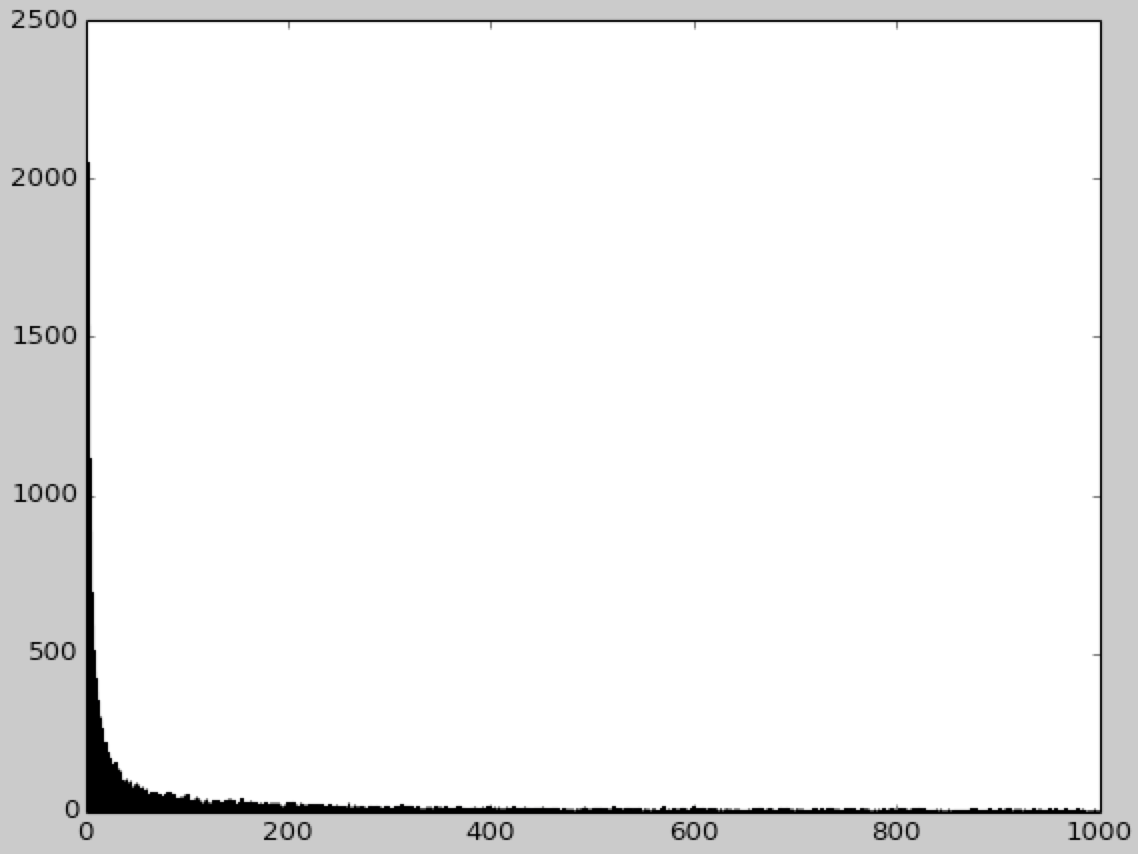
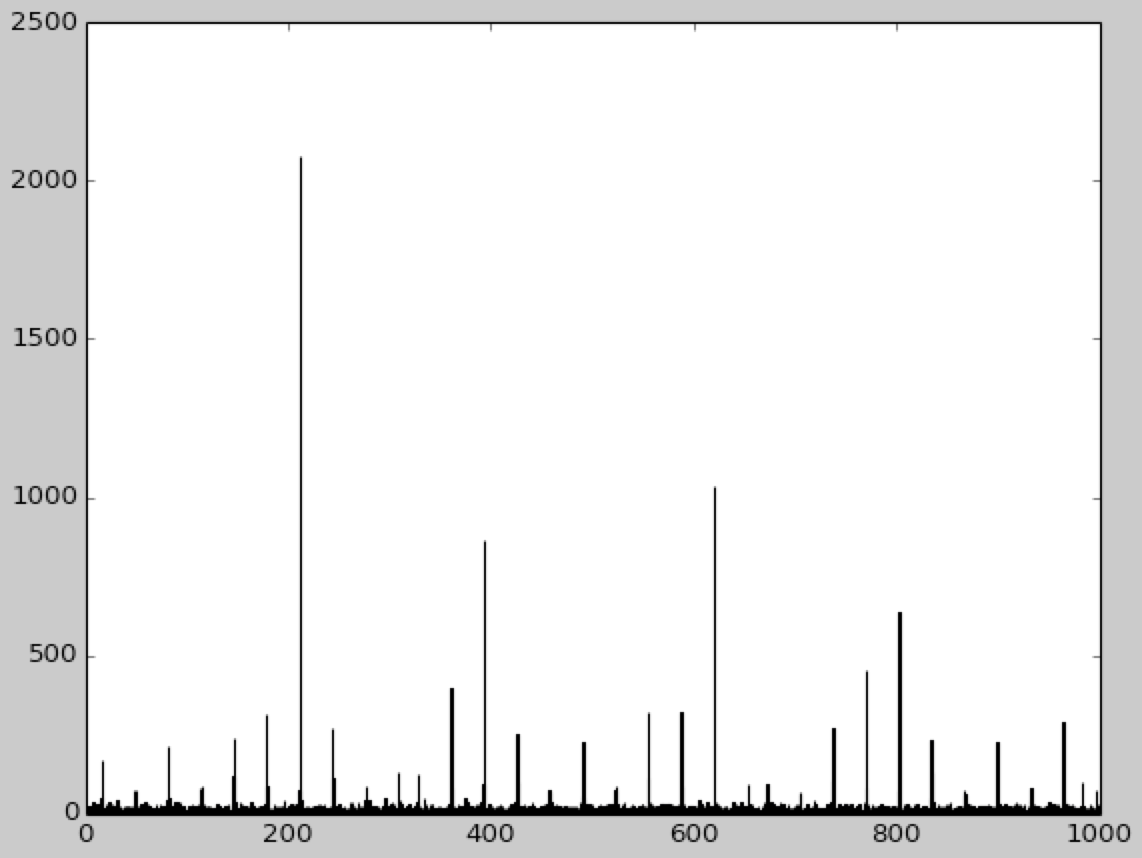
an example of such hashing algorithm. There are also couple of images in
the attachement that I have got from visualizing original zipfian
distribution and the hashed one. Usage example:
In psql:
create table abc as select generate_series(0, 999) as a, 0 as b;
pgbench script:
\set rnd random_zipfian(0, 1000000, 0.99)
\set key abs(hash(:rnd)) % 1000
begin;
update abc set b = b + 1 where a = :key;
end;
Any thoughts or suggestions?
[1] http://www.brianfrankcooper.net/home/publications/ycsb.pdf
[2] https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function
Thanks!
--
Ildar Musin
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 56.2 KB |
| hashed_zipfian.png | image/png | 75.5 KB |
| pgbench_hash.patch | text/plain | 1.7 KB |
{kind=link}
Responses
- Re: General purpose hashing func in pgbench at 2017-12-20 07:36:27 from Fabien COELHO
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Kamholz | 2017-12-20 06:03:38 | domain cast in parameterized vs. non-parameterized query |
| Previous Message | Tom Lane | 2017-12-20 05:57:12 | Re: [HACKERS] static assertions in C++ |