Re: [HACKERS] Lazy hash table for XidInMVCCSnapshot (helps Zipfian a bit)
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Yura Sokolov <funny(dot)falcon(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Sokolov Yura <funny(dot)falcon(at)postgrespro(dot)ru>, Robert Haas <robertmhaas(at)gmail(dot)com>, Alexander Korotkov <a(dot)korotkov(at)postgrespro(dot)ru>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org>, pgsql-hackers-owner(at)postgresql(dot)org |
| Subject: | Re: [HACKERS] Lazy hash table for XidInMVCCSnapshot (helps Zipfian a bit) |
| Date: | 2018-03-08 00:42:20 |
| Message-ID: | 057a9a95-19d2-05f0-17e2-f46ff20e9b3e@2ndquadrant.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 03/06/2018 06:23 AM, Yura Sokolov wrote:
> 05.03.2018 18:00, Tom Lane пишет:
>> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>>> Snapshots are static (we don't really add new XIDs into existing ones,
>>> right?), so why don't we simply sort the XIDs and then use bsearch to
>>> lookup values? That should fix the linear search, without need for any
>>> local hash table.
>>
>> +1 for looking into that, since it would avoid adding any complication
>> to snapshot copying. In principle, with enough XIDs in the snap, an
>> O(1) hash probe would be quicker than an O(log N) bsearch ... but I'm
>> dubious that we are often in the range where that would matter.
>> We do need to worry about the cost of snapshot copying, too.
>
> Sorting - is the first thing I've tried. Unfortunately, sorting
> itself eats too much cpu. Filling hash table is much faster.
>
I've been interested in the sort-based approach, so I've spent a bit of
time hacking on it (patch attached). It's much less invasive compared to
the hash-table, but Yura is right the hashtable gives better results.
I've tried to measure the benefits using the same script I shared on
Tuesday, but I kept getting really strange numbers. In fact, I've been
unable to even reproduce the results I shared back then. And after a bit
of head-scratching I think the script is useless - it can't possibly
generate snapshots with many XIDs because all the update threads sleep
for exactly the same time. And first one to sleep is first one to wake
up and commit, so most of the other XIDs are above xmax (and thus not
included in the snapshot). I have no idea why I got the numbers :-/
But with this insight, I quickly modified the script to also consume
XIDs by another thread (which simply calls txid_current). With that I'm
getting snapshots with as many XIDs as there are UPDATE clients (this
time I actually checked that using gdb).
And for a 60-second run the tps results look like this (see the attached
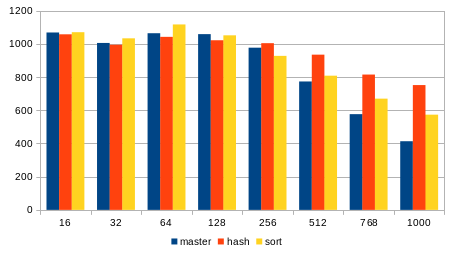
chart, showing the same data):
writers master hash sort
-----------------------------------------
16 1068 1057 1070
32 1005 995 1033
64 1064 1042 1117
128 1058 1021 1051
256 977 1004 928
512 773 935 808
768 576 815 670
1000 413 752 573
The sort certainly does improve performance compared to master, but it's
only about half of the hashtable improvement.
I don't know how much this simple workload resembles the YCSB benchmark,
but I seem to recall it's touching individual rows. In which case it's
likely worse due to the pg_qsort being more expensive than building the
hash table.
So I agree with Yura the sort is not a viable alternative to the hash
table, in this case.
> Can I rely on snapshots being static? May be then there is no need
> in separate raw representation and hash table. I may try to fill hash
> table directly in GetSnapshotData instead of lazy filling. Though it
> will increase time under lock, so it is debatable and should be
> carefully measured.
>
Yes, I think you can rely on snapshots not being modified later. That's
pretty much the definition of a snapshot.
You may do that in GetSnapshotData, but you certainly can't do that in
the for loop there. Not only we don't want to add more work there, but
you don't know the number of XIDs in that loop. And we don't want to
build hash tables for small number of XIDs.
One reason against building the hash table in GetSnapshotData is that
we'd build it even when the snapshot is never queried. Or when it is
queried, but we only need to check xmin/xmax.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| xid-sorted.patch | text/x-patch | 4.6 KB |
| xid-stats.tgz | application/x-compressed-tar | 2.4 KB |
|
image/png | 8.2 KB |
In response to
- Re: [HACKERS] Lazy hash table for XidInMVCCSnapshot (helps Zipfian a bit) at 2018-03-06 05:23:57 from Yura Sokolov
Responses
- Re: [HACKERS] Lazy hash table for XidInMVCCSnapshot (helps Zipfian a bit) at 2018-03-10 02:11:27 from Yura Sokolov
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Peter Eisentraut | 2018-03-08 00:53:46 | Re: INOUT parameters in procedures |
| Previous Message | Masahiko Sawada | 2018-03-08 00:42:13 | Re: [HACKERS] Subscription code improvements |