Patch: Write Amplification Reduction Method (WARM)
| From: | Pavan Deolasee <pavan(dot)deolasee(at)gmail(dot)com> |
|---|---|
| To: | pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Patch: Write Amplification Reduction Method (WARM) |
| Date: | 2016-08-31 16:45:33 |
| Message-ID: | CABOikdMNy6yowA+wTGK9RVd8iw+CzqHeQSGpW7Yka_4RSZ_LOQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi All,
As previously discussed [1], WARM is a technique to reduce write
amplification when an indexed column of a table is updated. HOT fails to
handle such updates and ends up inserting a new index entry in all indexes
of the table, irrespective of whether the index key has changed or not for
a specific index. The problem was highlighted by Uber's blog post [2], but
it was a well known problem and affects many workloads.
Simon brought up the idea originally within 2ndQuadrant and I developed it
further with inputs from my other colleagues and community members.
There were two important problems identified during the earlier discussion.
This patch addresses those issues in a simplified way. There are other
complex ideas to solve those issues, but as the results demonstrate, even a
simple approach will go far way in improving performance characteristics of
many workloads, yet keeping the code complexity to relatively low.
Two problems have so far been identified with the WARM design.
“*Duplicate Scan*” - Claudio Freire brought up a design flaw which may lead
an IndexScan to return same tuple twice or more, thus impacting the
correctness of the solution.
“*Root Pointer Search*” - Andres raised the point that it could be
inefficient to find the root line pointer for a tuple in the HOT or WARM
chain since it may require us to scan through the entire page.
The Duplicate Scan problem has correctness issues so could block WARM
completely. We propose the following solution:
We discussed a few ideas to address the "Duplicate Scan" problem. For
example, we can teach Index AMs to discard any duplicate (key, CTID) insert
requests. Or we could guarantee uniqueness by either only allowing updates
in one lexical order. While the former is a more complete solution to avoid
duplicate entries, searching through large number of keys for non-unique
indexes could be a drag on performance. The latter approach may not be
sufficient for many workloads. Also tracking increment/decrement for many
indexes will be non-trivial.
There is another problem with allowing many index entries pointing to the
same WARM chain. It will be non-trivial to know how many index entries are
currently pointing to the WARM chain and index/heap vacuum will throw up
more challenges.
Instead, what I would like to propose and the patch currently implements is
to restrict WARM update to once per chain. So the first non-HOT update to a
tuple or a HOT chain can be a WARM update. The chain can further be HOT
updated any number of times. But it can no further be WARM updated. This
might look too restrictive, but it can still bring down the number of
regular updates by almost 50%. Further, if we devise a strategy to convert
a WARM chain back to HOT chain, it can again be WARM updated. (This part is
currently not implemented). A good side effect of this simple strategy is
that we know there can maximum two index entries pointing to any given WARM
chain.
The other problem Andres brought up can be solved by storing the root line
pointer offset in the t_ctid field of the last tuple in the update chain.
Barring some aborted update case, usually it's the last tuple in the update
chain that will be updated, hence it seems logical and sufficient if we can
find the root line pointer while accessing that tuple. Note that the t_ctid
field in the latest tuple is usually useless and is made to point to
itself. Instead, I propose to use a bit from t_infomask2 to identify the
LATEST tuple in the chain and use OffsetNumber field in t_ctid to store
root line pointer offset. For rare aborted update case, we can scan the
heap page and find root line pointer is a hard way.
Index Recheck
--------------------
As the original proposal explains, while doing index scan we must recheck
if the heap tuple matches the index keys. This has to be done only when the
chain is marked as a WARM chain. Currently we do that by setting the last
free bit in t_infomask2 to HEAP_WARM_TUPLE. The bit is set on the tuple
that gets WARM updated and all subsequent tuples in the chain. But the
information can subsequently be copied to root line pointer when it's
converted to a LP_REDIRECT line pointer.
Since each index AM has its own view of the index tuples, each AM must
implement its "amrecheck" routine. This routine to used to confirm that a
tuple returned from a WARM chain indeed satisfies the index keys. If the
index AM does not implement "amrecheck" routine, WARM update is disabled on
a table which uses such an index. The patch currently implements
"amrecheck" routines for hash and btree indexes. Hence a table with GiST or
GIN index will not honour WARM updates.
Results
----------
We used a customised pgbench workload to test the feature. In particular,
the pgbench_accounts table was widened to include many more columns and
indexes. We also added an index on "abalance" field which gets updated in
every transaction. This replicates a workload where there are many indexes
on a table and an update changes just one index key.
CREATE TABLE pgbench_accounts (
aid bigint,
bid bigint,
abalance bigint,
filler1 text DEFAULT md5(random()::text),
filler2 text DEFAULT md5(random()::text),
filler3 text DEFAULT md5(random()::text),
filler4 text DEFAULT md5(random()::text),
filler5 text DEFAULT md5(random()::text),
filler6 text DEFAULT md5(random()::text),
filler7 text DEFAULT md5(random()::text),
filler8 text DEFAULT md5(random()::text),
filler9 text DEFAULT md5(random()::text),
filler10 text DEFAULT md5(random()::text),
filler11 text DEFAULT md5(random()::text),
filler12 text DEFAULT md5(random()::text)
);
CREATE UNIQUE INDEX pgb_a_aid ON pgbench_accounts(aid);
CREATE INDEX pgb_a_abalance ON pgbench_accounts(abalance);
CREATE INDEX pgb_a_filler1 ON pgbench_accounts(filler1);
CREATE INDEX pgb_a_filler2 ON pgbench_accounts(filler2);
CREATE INDEX pgb_a_filler3 ON pgbench_accounts(filler3);
CREATE INDEX pgb_a_filler4 ON pgbench_accounts(filler4);
These tests are run on c3.4xlarge AWS instances, with 30GB of RAM, 16 vCPU
and 2x160GB SSD. Data and WAL were mounted on a separate SSD.
The scale factor of 700 was chosen to ensure that the database does not fit
in memory and implications of additional write activity is evident.
The actual transactional tests would just update the pgbench_accounts table:
\set aid random(1, 100000 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
END;
The tests were run for a long duration of 16 hrs each with 16 pgbench
clients to ensure that effects of the patch are captured correctly.
Headline TPS numbers:
Master:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 65552986
latency average: 14.059 ms
*tps = 1138.072117 (including connections establishing)*
tps = 1138.072156 (excluding connections establishing)
WARM:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 116168454
latency average: 7.933 ms
*tps = 2016.812924 (including connections establishing)*
tps = 2016.812997 (excluding connections establishing)
So WARM shows about *77% increase* in TPS. Note that these are fairly long
running tests with nearly 100M transactions and the tests show a steady
performance.
We also measured the amount of WAL generated by Master and WARM per
transaction. While master generated 34967 bytes of WAL per transaction,
WARM generated 18421 bytes of WAL per transaction.
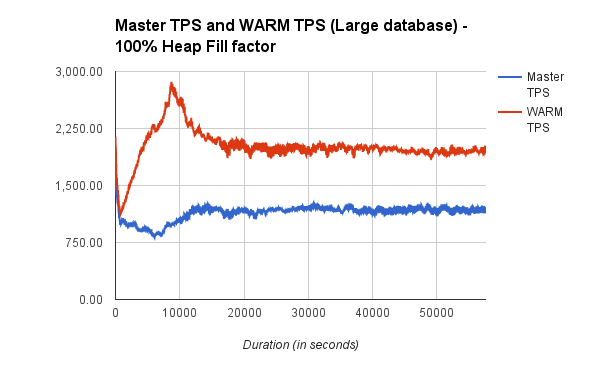
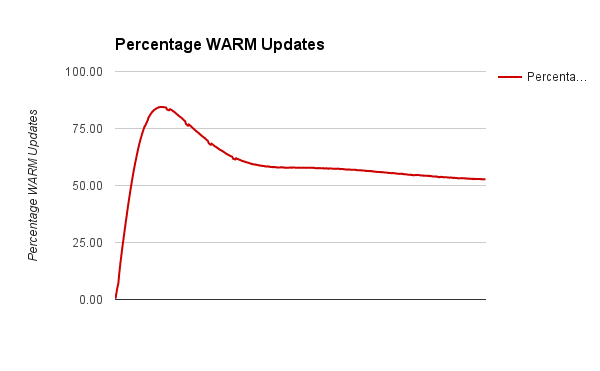
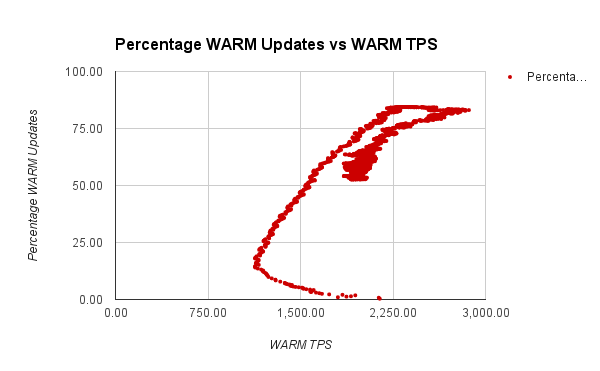
We plotted a moving average of TPS against time and also against the
percentage of WARM updates. Clearly higher the number of WARM updates,
higher is the TPS. A graph showing percentage of WARM updates is also
plotted and it shows a steady convergence to 50% mark with time.
We repeated the same tests starting with 90% heap fill factor such that
there are many more WARM updates. Since with 90% fill factor and in
combination with HOT pruning, most initial updates will be WARM updates and
that impacts TPS positively. WARM shows nearly *150% increase *in TPS for
that workload.
Master:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 78134617
latency average: 11.795 ms
*tps = 1356.503629 (including connections establishing)*
tps = 1356.503679 (excluding connections establishing)
WARM:
transaction type: update.sql
scaling factor: 700
query mode: simple
number of clients: 16
number of threads: 8
duration: 57600 s
number of transactions actually processed: 196782770
latency average: 4.683 ms
*tps = 3416.364822 (including connections establishing)*
tps = 3416.364949 (excluding connections establishing)
In this case, master produced ~49000 bytes of WAL per transaction where as
WARM produced ~14000 bytes of WAL per transaction.
I concede that we haven't yet done many tests to measure overhead of the
technique, especially in circumstances where WARM may not be very useful.
What I have in mind are couple of tests:
- With many indexes and a good percentage of them requiring update
- A mix of read-write workload
Any other ideas to do that are welcome.
Concerns:
--------------
The additional heap recheck may have negative impact on performance. We
tried to measure this by running a SELECT only workload for 1hr after 16hr
test finished. But the TPS did not show any negative impact. The impact
could be more if the update changes many index keys, something these tests
don't test.
The patch also changes things such that index tuples are always returned
because they may be needed for recheck. It's not clear if this is something
to be worried about, but we could try to further fine tune this change.
There seems to be some modularity violations since index AM needs to access
some of the executor stuff to form index datums. If that's a real concern,
we can look at improving amrecheck signature so that it gets index datums
from the caller.
The patch uses remaining 2 free bits in t_infomask, thus closing any
further improvements which may need to use heap tuple flags. During the
patch development we tried several other approaches such as reusing
3-higher order bits in OffsetNumber since the current max BLCKSZ limits the
MaxOffsetNumber to 8192 and that can be represented in 13 bits. We finally
reverted that change to keep the patch simple. But there is clearly a way
to free up more bits if required.
Converting WARM chains back to HOT chains (VACUUM ?)
---------------------------------------------------------------------------------
The current implementation of WARM allows only one WARM update per chain.
This
simplifies the design and addresses certain issues around duplicate scans.
But
this also implies that the benefit of WARM will be no more than 50%, which
is
still significant, but if we could return WARM chains back to normal
status, we
could do far more WARM updates.
A distinct property of a WARM chain is that at least one index has more than
one live index entries pointing to the root of the chain. In other words,
if we
can remove duplicate entry from every index or conclusively prove that there
are no duplicate index entries for the root line pointer, the chain can
again
be marked as HOT.
Here is one idea, but more thoughts/suggestions are most welcome.
A WARM chain has two parts, separated by the tuple that caused WARM update.
All
tuples in each part has matching index keys, but certain index keys may not
match between these two parts. Lets say we mark heap tuples in each part
with a
special Red-Blue flag. The same flag is replicated in the index tuples. For
example, when new rows are inserted in a table, they are marked with Blue
flag
and the index entries associated with those rows are also marked with Blue
flag. When a row is WARM updated, the new version is marked with Red flag
and
the new index entry created by the update is also marked with Red flag.
Heap chain: lp [1] [2] [3] [4]
[aaaa, 1111]B -> [aaaa, 1111]B -> [bbbb, 1111]R -> [bbbb, 1111]R
Index1: (aaaa)B points to 1 (satisfies only tuples marked with B)
(bbbb)R points to 1 (satisfies only tuples marked with R)
Index2: (1111)B points to 1 (satisfies both B and R tuples)
It's clear that for indexes with Red and Blue pointers, a heap tuple with
Blue
flag will be reachable from Blue pointer and that with Red flag will be
reachable from Red pointer. But for indexes which did not create a new
entry,
both Blue and Red tuples will be reachable from Blue pointer (there is no
Red
pointer in such indexes). So, as a side note, matching Red and Blue flags is
not enough from index scan perspective.
During first heap scan of VACUUM, we look for tuples with HEAP_WARM_TUPLE
set.
If all live tuples in the chain are either marked with Blue flag or Red flag
(but no mix of Red and Blue), then the chain is a candidate for HOT
conversion.
We remember the root line pointer and Red-Blue flag of the WARM chain in a
separate array.
If we have a Red WARM chain, then our goal is to remove Blue pointers and
vice
versa. But there is a catch. For Index2 above, there is only Blue pointer
and that must not be removed. IOW we should remove Blue pointer iff a Red
pointer exists. Since index vacuum may visit Red and Blue pointers in any
order, I think we will need another index pass to remove dead
index pointers. So in the first index pass we check which WARM candidates
have
2 index pointers. In the second pass, we remove the dead pointer and reset
Red
flag is the surviving index pointer is Red.
During the second heap scan, we fix WARM chain by clearing HEAP_WARM_TUPLE
flag
and also reset Red flag to Blue.
There are some more problems around aborted vacuums. For example, if vacuum
aborts after changing Red index flag to Blue but before removing the other
Blue
pointer, we will end up with two Blue pointers to a Red WARM chain. But
since
the HEAP_WARM_TUPLE flag on the heap tuple is still set, further WARM
updates
to the chain will be blocked. I guess we will need some special handling for
case with multiple Blue pointers. We can either leave these WARM chains
alone
and let them die with a subsequent non-WARM update or must apply
heap-recheck
logic during index vacuum to find the dead pointer. Given that vacuum-aborts
are not common, I am inclined to leave this case unhandled. We must still
check
for presence of multiple Blue pointers and ensure that we don't accidently
remove any of the Blue pointers and not clear WARM chains either.
Of course, the idea requires one bit each in index and heap tuple. There is
already a free bit in index tuple and I've some ideas to free up additional
bits in heap tuple (as mentioned above).
Further Work
------------------
1.The patch currently disables WARM updates on system relations. This is
mostly to keep the patch simple, but in theory we should be able to support
WARM updates on system tables too. It's not clear if its worth the
complexity though.
2. AFAICS both CREATE INDEX and CIC should just work fine, but need
validation for that.
3. GiST and GIN indexes are currently disabled for WARM. I don't see a
fundamental reason why they won't work once we implement "amrecheck"
method, but I don't understand those indexes well enough.
4. There are some modularity invasions I am worried about (is amrecheck
signature ok?). There are also couple of hacks around to get access to
index tuples during scans and I hope to get them correct during review
process, with some feedback.
5. Patch does not implement machinery to convert WARM chains into HOT
chains. I would give it go unless someone finds a problem with the idea or
has a better idea.
Thanks,
Pavan
[1] - https://www.postgresql.org/message-id/CABOikdMop5Rb_RnS2xF
dAXMZGSqcJ-P-BY2ruMd%2BbuUkJ4iDPw(at)mail(dot)gmail(dot)com
[2] - https://eng.uber.com/mysql-migration/
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 19.8 KB |
|
image/png | 11.3 KB |
|
image/png | 17.7 KB |
| 0001_track_root_lp_v2.patch | application/octet-stream | 25.4 KB |
| 0002_warm_updates_v2.patch | application/octet-stream | 90.2 KB |
Responses
- Re: Patch: Write Amplification Reduction Method (WARM) at 2016-08-31 17:08:23 from Claudio Freire
- Re: Patch: Write Amplification Reduction Method (WARM) at 2016-08-31 18:34:41 from Pavan Deolasee
- Re: Patch: Write Amplification Reduction Method (WARM) at 2016-08-31 20:03:29 from Bruce Momjian
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Lane | 2016-08-31 16:53:30 | Re: pg_sequence catalog |
| Previous Message | Greg Stark | 2016-08-31 16:36:11 | Re: autonomous transactions |