Re: Speed up Clog Access by increasing CLOG buffers
| From: | Amit Kapila <amit(dot)kapila16(at)gmail(dot)com> |
|---|---|
| To: | Jesper Pedersen <jesper(dot)pedersen(at)redhat(dot)com> |
| Cc: | pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Speed up Clog Access by increasing CLOG buffers |
| Date: | 2015-11-17 06:50:36 |
| Message-ID: | CAA4eK1L_snxM_JcrzEstNq9P66++F4kKFce=1r5+D1vzPofdtg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Mon, Sep 21, 2015 at 6:25 PM, Jesper Pedersen <jesper(dot)pedersen(at)redhat(dot)com
> wrote:
> On 09/18/2015 11:11 PM, Amit Kapila wrote:
>
>> I have done various runs on an Intel Xeon 28C/56T w/ 256Gb mem and 2 x
>>> RAID10 SSD (data + xlog) with Min(64,).
>>>
>>>
>>> The benefit with this patch could be seen at somewhat higher
>> client-count as you can see in my initial mail, can you please
>> once try with client count > 64?
>>
>>
> Client count were from 1 to 80.
>
> I did do one run with Min(128,) like you, but didn't see any difference in
> the result compared to Min(64,), so focused instead in the sync_commit
> on/off testing case.
>
I think the main focus for test in this area would be at higher client
count. At what scale factors have you taken the data and what are
the other non-default settings you have used. By the way, have you
tried by dropping and recreating the database and restarting the server
after each run, can you share the exact steps you have used to perform
the tests. I am not sure why it is not showing the benefit in your testing,
may be the benefit is on some what more higher end m/c or it could be
that some of the settings used for test are not same as mine or the way
to test the read-write workload of pgbench is different.
In anycase, I went ahead and tried further reducing the CLogControlLock
contention by grouping the transaction status updates. The basic idea
is same as is used to reduce the ProcArrayLock contention [1] which is to
allow one of the proc to become leader and update the transaction status for
other active transactions in system. This has helped to reduce the
contention
around CLOGControlLock. Attached patch group_update_clog_v1.patch
implements this idea.
I have taken performance data with this patch to see the impact at
various scale-factors. All the data is for cases when data fits in shared
buffers and is taken against commit - 5c90a2ff on server with below
configuration and non-default postgresql.conf settings.
Performance Data
-----------------------------
RAM - 500GB
8 sockets, 64 cores(Hyperthreaded128 threads total)
Non-default parameters
------------------------------------
max_connections = 300
shared_buffers=8GB
min_wal_size=10GB
max_wal_size=15GB
checkpoint_timeout =35min
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.9
wal_buffers = 256MB
Refer attached files for performance data.
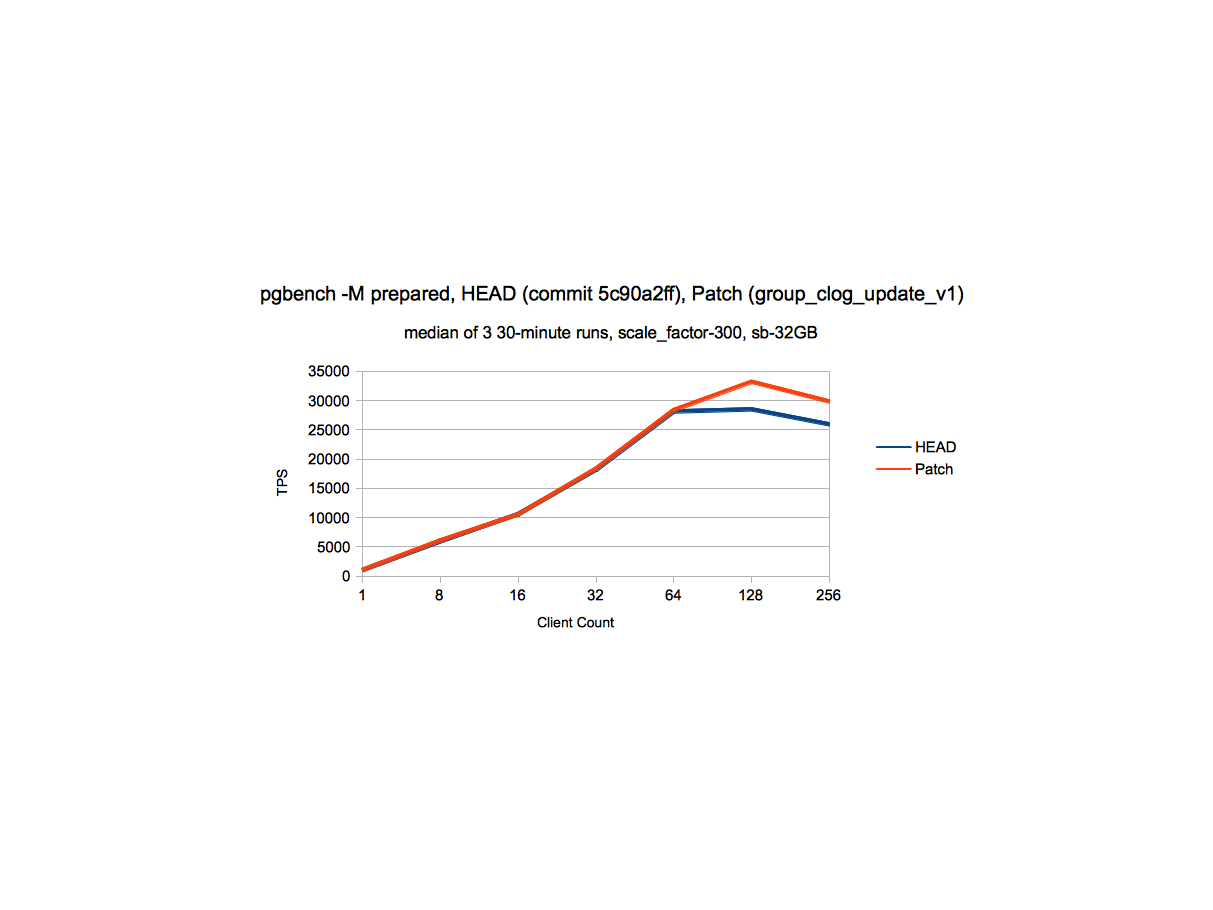
sc_300_perf.png - This data indicates that at scale_factor 300, there is a
gain of ~15% at higher client counts, without degradation at lower client
count.
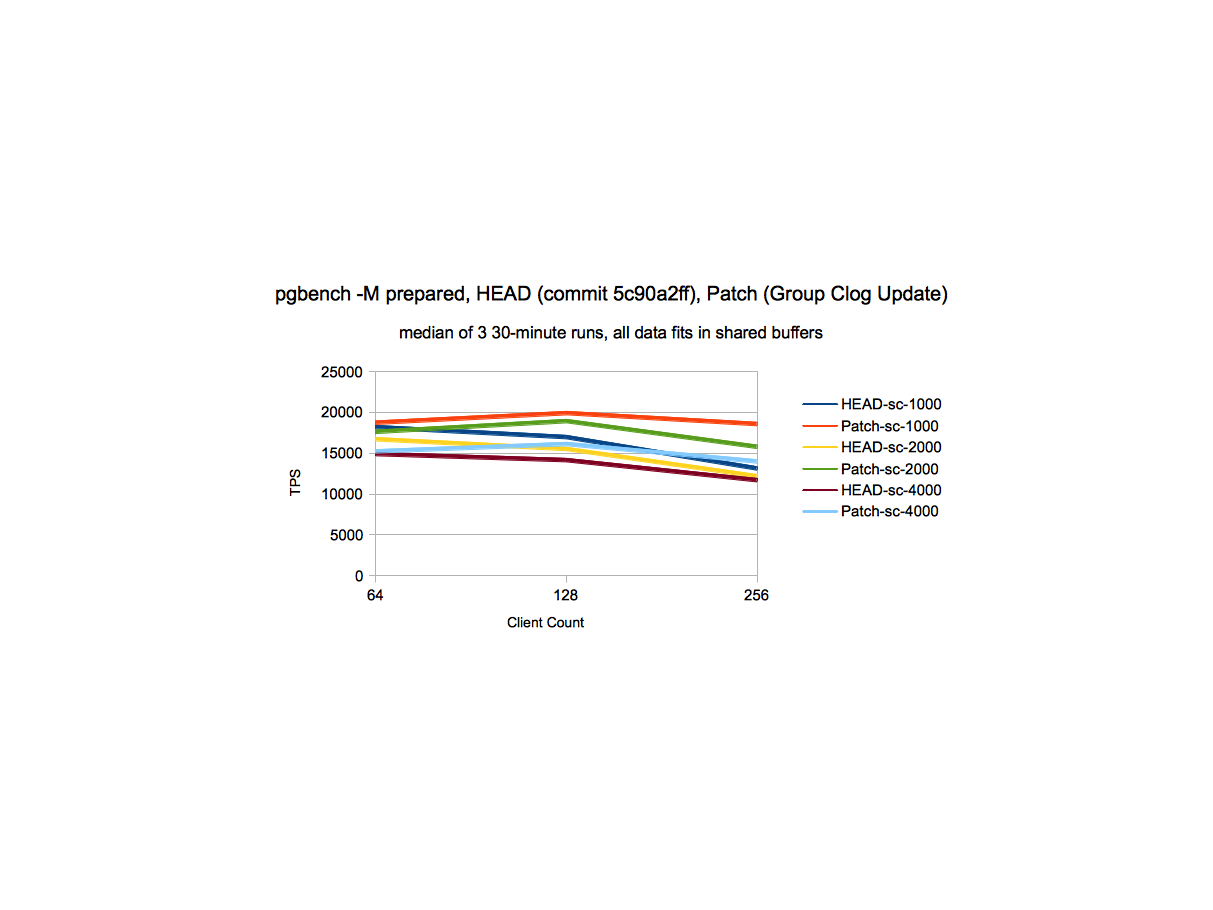
different_sc_perf.png - At various scale factors, there is a gain from
~15% to 41% at higher client counts and in some cases we see gain
of ~5% at somewhat moderate client count (64) as well.
perf_write_clogcontrollock_data_v1.ods - Detailed performance data at
various client counts and scale factors.
Feel free to ask for more details if the data in attached files is not
clear.
Below is the LWLock_Stats information with and without patch:
Stats Data
---------
A. scale_factor = 300; shared_buffers=32GB; client_connections - 128
HEAD - 5c90a2ff
----------------
CLogControlLock Data
------------------------
PID 94100 lwlock main 11: shacq 678672 exacq 326477 blk 204427 spindelay
8532 dequeue self 93192
PID 94129 lwlock main 11: shacq 757047 exacq 363176 blk 207840 spindelay
8866 dequeue self 96601
PID 94115 lwlock main 11: shacq 721632 exacq 345967 blk 207665 spindelay
8595 dequeue self 96185
PID 94011 lwlock main 11: shacq 501900 exacq 241346 blk 173295 spindelay
7882 dequeue self 78134
PID 94087 lwlock main 11: shacq 653701 exacq 314311 blk 201733 spindelay
8419 dequeue self 92190
After Patch group_update_clog_v1
----------------
CLogControlLock Data
------------------------
PID 100205 lwlock main 11: shacq 836897 exacq 176007 blk 116328 spindelay
1206 dequeue self 54485
PID 100034 lwlock main 11: shacq 437610 exacq 91419 blk 77523 spindelay 994
dequeue self 35419
PID 100175 lwlock main 11: shacq 748948 exacq 158970 blk 114027 spindelay
1277 dequeue self 53486
PID 100162 lwlock main 11: shacq 717262 exacq 152807 blk 115268 spindelay
1227 dequeue self 51643
PID 100214 lwlock main 11: shacq 856044 exacq 180422 blk 113695 spindelay
1202 dequeue self 54435
The above data indicates that contention due to CLogControlLock is
reduced by around 50% with this patch.
The reasons for remaining contention could be:
1. Readers of clog data (checking transaction status data) can take
Exclusive CLOGControlLock when reading the page from disk, this can
contend with other Readers (shared lockers of CLogControlLock) and with
exclusive locker which updates transaction status. One of the ways to
mitigate this contention is to increase the number of CLOG buffers for which
patch has been already posted on this thread.
2. Readers of clog data (checking transaction status data) takes shared
CLOGControlLock which can contend with exclusive locker (Group leader) which
updates transaction status. I have tried to reduce the amount of work done
by group leader, by allowing group leader to just read the Clog page once
for all the transactions in the group which updated the same CLOG page
(idea similar to what we currently we use for updating the status of
transactions
having sub-transaction tree), but that hasn't given any further performance
boost,
so I left it.
I think we can use some other ways as well to reduce the contention around
CLOGControlLock by doing somewhat major surgery around SLRU like using
buffer pools similar to shared buffers, but this idea gives us moderate
improvement without much impact on exiting mechanism.
Thoughts?
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| group_update_clog_v1.patch | application/octet-stream | 12.5 KB |
|
image/png | 66.2 KB |
| different_sc_perf.png | image/png | 82.0 KB |
| perf_write_clogcontrollock_data_v1.ods | application/vnd.oasis.opendocument.spreadsheet | 24.8 KB |
{kind=link}
In response to
- Re: Speed up Clog Access by increasing CLOG buffers at 2015-09-21 12:55:45 from Jesper Pedersen
Responses
- Re: Speed up Clog Access by increasing CLOG buffers at 2015-11-17 09:15:35 from Simon Riggs
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Kyotaro HORIGUCHI | 2015-11-17 07:09:25 | Re: Making tab-complete.c easier to maintain |
| Previous Message | konstantin knizhnik | 2015-11-17 06:42:54 | Re: Question concerning XTM (eXtensible Transaction Manager API) |