Re: CLOG contention
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: CLOG contention |
| Date: | 2011-12-22 16:20:13 |
| Message-ID: | CA+TgmoZoT3mc8jsisnGi7S-TMiSt_VQwXTA50FP2CWWY0Z9BVg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Thu, Dec 22, 2011 at 1:04 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> I understand why you say that and take no offence. All I can say is
> last time I has access to a good test rig and well structured
> reporting and analysis I was able to see evidence of what I described
> to you here.
>
> I no longer have that access, which is the main reason I've not done
> anything in the last few years. We both know you do have good access
> and that's the main reason I'm telling you about it rather than just
> doing it myself.
Right. But I need more details. If I know what to test and how to
test it, I can do it. Otherwise, I'm just guessing. I dislike
guessing.
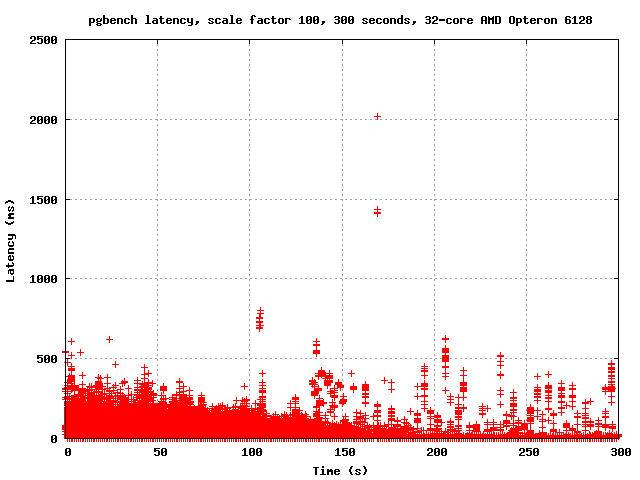
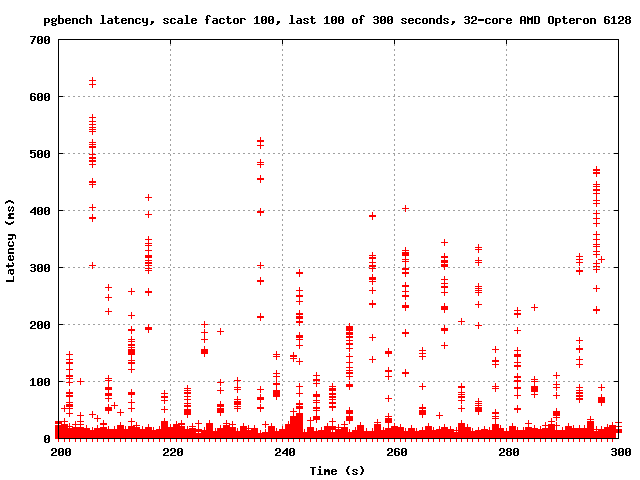
You mentioned "latency" so this morning I ran pgbench with -l and
graphed the output. There are latency spikes every few seconds. I'm
attaching the overall graph as well as the graph of the last 100
seconds, where the spikes are easier to see clearly. Now, here's the
problem: it seems reasonable to hypothesize that the spikes are due to
CLOG page replacement since the frequency is at least plausibly right,
but this is obviously not enough to prove that conclusively. Ideas?
Also, if it is that, what do we do about it? I don't think any of the
ideas proposed so far are going to help much. Increasing the number
of CLOG buffers isn't going to fix the problem that once they're all
dirty, you have to write and fsync one before pulling in the next one.
Striping might actually make it worse - everyone will move to the
next buffer right around the same time, and instead of everybody
waiting for one fsync, they'll each be waiting for their own. Maybe
the solution is to have the background writer keep an eye on how many
CLOG buffers are dirty and start writing them out if the number gets
too big.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 6.5 KB |
|
image/png | 6.4 KB |
In response to
- Re: CLOG contention at 2011-12-22 06:04:01 from Simon Riggs
Responses
- Re: CLOG contention at 2011-12-24 09:25:05 from Simon Riggs
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Andrew Dunstan | 2011-12-22 16:26:18 | Re: Typed hstore proposal |
| Previous Message | Kevin Grittner | 2011-12-22 16:16:25 | Re: Page Checksums + Double Writes |