Re: There's random access and then there's random access
| From: | Gregory Stark <stark(at)enterprisedb(dot)com> |
|---|---|
| To: | "pgsql-hackers list" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: There's random access and then there's random access |
| Date: | 2007-12-04 17:46:23 |
| Message-ID: | 87ve7egxow.fsf@oxford.xeocode.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
"Gregory Stark" <stark(at)enterprisedb(dot)com> writes:
> The two interfaces I'm aware of for this are posix_fadvise() and libaio.
> I've run tests with a synthetic benchmark which generates a large file then
> reads a random selection of blocks from within it using either synchronous
> reads like we do now or either of those interfaces. I saw impressive speed
> gains on a machine with only three drives in a raid array. I did this a
> while ago so I don't have the results handy. I'll rerun the tests again and
> post them.
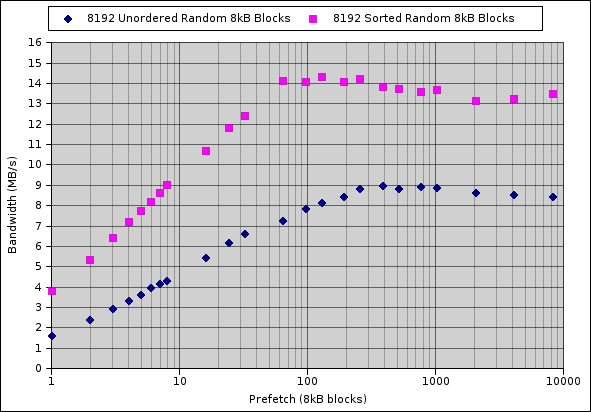
Here's the results of running the synthetic test program on a 3-drive raid
array. Note that the results *exceeded* the 3x speedup I expected, even for
ordered blocks. Either the drive (or the OS) is capable of reordering the
block requests better than the offset into the file would appear or some other
effect is kicking in.
The test is with an 8GB file, picking 8,192 random 8k blocks from within it.
The pink diamonds represent the bandwidth obtained if the random blocks are
sorted before fetching (like a bitmap indexscan) and the blue if they're
unsorted.
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 15.2 KB |
| test-pfa-results | application/octet-stream | 2.2 KB |
| test-pfa.c | text/x-csrc | 8.9 KB |
In response to
- There's random access and then there's random access at 2007-12-02 13:17:09 from Gregory Stark
Responses
- Re: There's random access and then there's random access at 2007-12-04 18:56:32 from Mark Mielke
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Alvaro Herrera | 2007-12-04 17:46:38 | Re: weird - invalid string enlargement request size |
| Previous Message | Walter Cruz | 2007-12-04 17:18:36 | weird - invalid string enlargement request size |