Re: [PERFORM] Slow query: bitmap scan troubles
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: [PERFORM] Slow query: bitmap scan troubles |
| Date: | 2013-01-06 23:03:05 |
| Message-ID: | 8539.1357513385@sss.pgh.pa.us |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers pgsql-performance |
Simon Riggs <simon(at)2ndQuadrant(dot)com> writes:
> On 6 January 2013 18:58, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> IIRC, one of my very first attempts to deal with this was to charge
>> random_page_cost per level of index descended. This was such a horrid
>> overestimate that it never went anywhere. I think that reflects that in
>> practical applications, the upper levels of the index tend to stay in
>> cache. We could ignore I/O on that assumption and still try to model
>> CPU costs of the descent, which is basically what Jeff is proposing.
>> My objection to his formula is mainly that it ignores physical index
>> size, which I think is important to include somehow for the reasons
>> I explained in my other message.
> Having a well principled approach will help bring us towards a
> realistic estimate.
I thought about this some more and came up with what might be a
reasonably principled compromise. Assume that we know there are N
leaf entries in the index (from VACUUM stats) and that we know the
root page height is H (from looking at the btree metapage). (Note:
H starts at zero for a single-page index.) If we assume that the
number of tuples per page, P, is more or less uniform across leaf
and upper pages (ie P is the fanout for upper pages), then we have
N/P = number of leaf pages
N/P/P = number of level 1 pages
N/P^3 = number of level 2 pages
N/P^(h+1) = number of level h pages
Solving for the minimum P that makes N/P^(H+1) <= 1, we get
P = ceil(exp(ln(N)/(H+1)))
as an estimate of P given the known N and H values.
Now, if we consider only CPU costs of index descent, we expect
about log2(P) comparisons to be needed on each of the H upper pages
to be descended through, that is we have total descent cost
cpu_index_tuple_cost * H * log2(P)
If we ignore the ceil() step as being a second-order correction, this
can be simplified to
cpu_index_tuple_cost * H * log2(N)/(H+1)
I propose this, rather than Jeff's formula of cpu_index_tuple_cost *
log2(N), as our fudge factor. The reason I like this better is that
the additional factor of H/(H+1) provides the correction I want for
bloated indexes: if an index is bloated, the way that reflects into
the cost of any particular search is that the number of pages to be
descended through is larger than otherwise. The correction is fairly
small, particularly for large indexes, but that seems to be what's
expected given the rest of our discussion.
We could further extend this by adding some I/O charge when the index is
sufficiently large, as per Simon's comments, but frankly I think that's
unnecessary. Unless the fan-out factor is really awful, practical-sized
indexes probably have all their upper pages in memory. What's more, per
my earlier comment, when you start to think about tables so huge that
that's not true it really doesn't matter if we charge another
random_page_cost or two for an indexscan --- it'll still be peanuts
compared to the seqscan alternative.
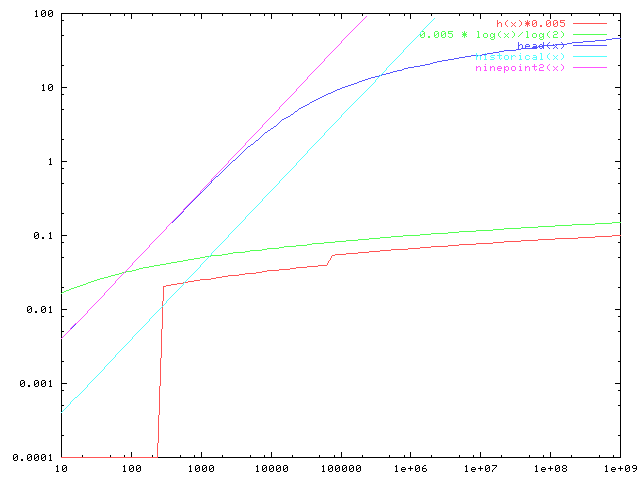
To illustrate the behavior of this function, I've replotted my previous
graph, still taking the assumed fanout to be 256 tuples/page. I limited
the range of the functions to 0.0001 to 100 to keep the log-scale graph
readable, but actually the H/(H+1) formulation would charge zero for
indexes of less than 256 tuples. I think it's significant (and a good
thing) that this curve is nowhere significantly more than the historical
pre-9.2 fudge factor.
Thoughts?
regards, tom lane
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 5.1 KB |
| unknown_filename | text/plain | 526 bytes |
In response to
- Re: [PERFORM] Slow query: bitmap scan troubles at 2013-01-06 19:47:48 from Simon Riggs
Responses
- Re: [PERFORM] Slow query: bitmap scan troubles at 2013-01-06 23:17:23 from Tom Lane
- Re: [PERFORM] Slow query: bitmap scan troubles at 2013-01-07 00:03:04 from Simon Riggs
- Re: [PERFORM] Slow query: bitmap scan troubles at 2013-01-07 17:35:51 from Tom Lane
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Lane | 2013-01-06 23:17:23 | Re: [PERFORM] Slow query: bitmap scan troubles |
| Previous Message | Simon Riggs | 2013-01-06 21:58:49 | Re: Skip checkpoint on promoting from streaming replication |
Browse pgsql-performance by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Lane | 2013-01-06 23:17:23 | Re: [PERFORM] Slow query: bitmap scan troubles |
| Previous Message | Simon Riggs | 2013-01-06 19:47:48 | Re: [PERFORM] Slow query: bitmap scan troubles |