Better LWLocks with compare-and-swap (9.4)
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgreSQL(dot)org> |
| Subject: | Better LWLocks with compare-and-swap (9.4) |
| Date: | 2013-05-13 12:50:03 |
| Message-ID: | 5190E17B.9060804@vmware.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
I've been working on-and-off on the WAL-insert scaling patch. It's in
pretty good shape now, and I'll post it shortly, but one thing I noticed
is that it benefits a lot from using an atomic compare-and-swap
instruction for the contention-critical part.
I realized that we could also use compare-and-swap to make LWLocks scale
better. The LWLock struct is too large to compare-and-swap atomically,
but we can still use CAS to increment/decrement the shared/exclusive
counters, when there's no need to manipulate the wait queue. That would
help with workloads where you have a lot of CPUs, and a lot of backends
need to acquire the same lwlock in shared mode, but there's no real
contention (ie. few exclusive lockers).
pgbench -S is such a workload. With 9.3beta1, I'm seeing this profile,
when I run "pgbench -S -c64 -j64 -T60 -M prepared" on a 32-core Linux
machine:
- 64.09% postgres postgres [.] tas
- tas
- 99.83% s_lock
- 53.22% LWLockAcquire
+ 99.87% GetSnapshotData
- 46.78% LWLockRelease
GetSnapshotData
+ GetTransactionSnapshot
+ 2.97% postgres postgres [.] tas
+ 1.53% postgres libc-2.13.so [.] 0x119873
+ 1.44% postgres postgres [.] GetSnapshotData
+ 1.29% postgres [kernel.kallsyms] [k] arch_local_irq_enable
+ 1.18% postgres postgres [.] AllocSetAlloc
...
So, on this test, a lot of time is wasted spinning on the mutex of
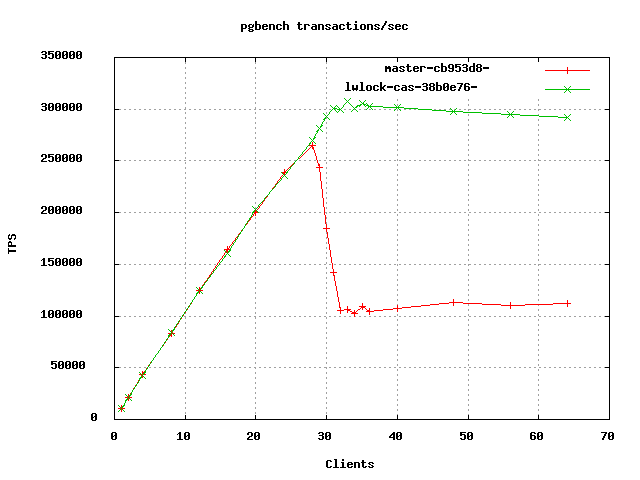
ProcArrayLock. If you plot a graph of TPS vs. # of clients, there is a
surprisingly steep drop in performance once you go beyond 29 clients
(attached, pgbench-lwlock-cas-local-clients-sets.png, red line). My
theory is that after that point all the cores are busy, and processes
start to be sometimes context switched while holding the spinlock, which
kills performance. Has anyone else seen that pattern? Curiously, I don't
see that when connecting pgbench via TCP over localhost, only when
connecting via unix domain sockets. Overall performance is higher over
unix domain sockets, so I guess the TCP layer adds some overhead,
hurting performance, and also affects scheduling somehow, making the
steep drop go away.
Using a compare-and-swap instruction in place of spinning solves the
problem (green line in attached graph). This needs some more testing
with different workloads to make sure it doesn't hurt other scenarios,
but I don't think it will. I'm also waiting for a colleague to test this
on a different machine, where he saw a similar steep drop in performance.
The attached patch is still work-in-progress. There needs to be a
configure test and fallback to spinlock if a CAS instruction is not
available. I used the gcc __sync_val_compare_and_swap() builtin
directly, that needs to be abstracted. Also, in the case that the wait
queue needs to be manipulated, the code spins on the CAS instruction,
but there is no delay mechanism like there is on a regular spinlock;
that needs to be added in somehow.
- Heikki
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 5.5 KB |
| lwlock-cas-2.patch | text/x-diff | 10.5 KB |
Responses
- Re: Better LWLocks with compare-and-swap (9.4) at 2013-05-13 14:21:27 from Merlin Moncure
- Re: Better LWLocks with compare-and-swap (9.4) at 2013-05-15 22:08:19 from Daniel Farina
- Re: Better LWLocks with compare-and-swap (9.4) at 2013-05-16 12:25:34 from Stephen Frost
- Re: Better LWLocks with compare-and-swap (9.4) at 2013-05-18 00:52:25 from Dickson S. Guedes
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Heikki Linnakangas | 2013-05-13 13:15:20 | Re: lock support for aarch64 |
| Previous Message | ktm@rice.edu | 2013-05-13 12:49:09 | Re: corrupt pages detected by enabling checksums |