Re: [PERFORM] Slow query: bitmap scan troubles
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: [PERFORM] Slow query: bitmap scan troubles |
| Date: | 2013-01-06 18:18:03 |
| Message-ID: | 17517.1357496283@sss.pgh.pa.us |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers pgsql-performance |
Jeff Janes <jeff(dot)janes(at)gmail(dot)com> writes:
> On Saturday, January 5, 2013, Tom Lane wrote:
>> Jeff Janes <jeff(dot)janes(at)gmail(dot)com <javascript:;>> writes:
>>> One thing which depends on the index size which, as far as I can tell, is
>>> not currently being counted is the cost of comparing the tuples all the way
>>> down the index. This would be proportional to log2(indextuples) *
>>> cpu_index_tuple_cost, or maybe log2(indextuples) *
>>> (cpu_index_tuple_cost+cpu_operator_cost), or something like that.
>> Yeah, I know. I've experimented repeatedly over the years with trying
>> to account explicitly for index descent costs. But every time, anything
>> that looks even remotely principled turns out to produce an overly large
>> correction that results in bad plan choices. I don't know exactly why
>> this is, but it's true.
> log2(indextuples) * cpu_index_tuple_cost should produce pretty darn small
> corrections, at least if cost parameters are at the defaults. Do you
> remember if that one of the ones you tried?
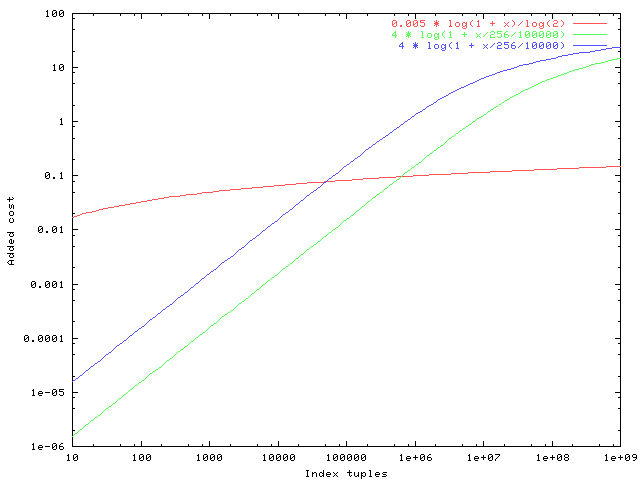
Well, a picture is worth a thousand words, so see the attached plot of
the various proposed corrections for indexes of 10 to 1e9 tuples. For
purposes of argument I've supposed that the index has loading factor
256 tuples/page, and I used the default values of random_page_cost and
cpu_index_tuple_cost. The red line is your proposal, the green one is
mine, the blue one is current HEAD behavior.
Both the blue and green lines get to values that might be thought
excessively high for very large indexes, but I doubt that that really
matters: if the table contains a billion rows, the cost of a seqscan
will be so high that it'll hardly matter if we overshoot the cost of an
index probe a bit. (Also, once the table gets that large it's debatable
whether the upper index levels all fit in cache, so charging an extra
random_page_cost or so isn't necessarily unrealistic.)
The real problem though is at the other end of the graph: I judge that
the red line represents an overcorrection for indexes of a few thousand
tuples.
It might also be worth noting that for indexes of a million or so
tuples, we're coming out to about the same place anyway.
>> One other point is that I think it is better for any such correction
>> to depend on the index's total page count, not total tuple count,
>> because otherwise two indexes that are identical except for bloat
>> effects will appear to have identical costs.
> This isn't so. A bloated index will be estimated to visit more pages than
> an otherwise identical non-bloated index, and so have a higher cost.
No it won't, or at least not reliably so, if there is no form of
correction for index descent costs. For instance, in a probe into a
unique index, we'll always estimate that we're visiting a single index
tuple on a single index page. The example you show is tweaked to ensure
that it estimates visiting more than one index page, and in that context
the leaf-page-related costs probably do scale with bloat; but they won't
if the query is only looking for one index entry.
> For the bloated index, this correction might even be too harsh. If the
> index is bloated by having lots of mostly-empty pages, then this seems
> fair. If it is bloated by having lots of entirely empty pages that are not
> even linked into the tree, then those empty ones will never be visited and
> so it shouldn't be penalized.
It's true that an un-linked empty page adds no cost by itself. But if
there are a lot of now-empty pages, that probably means a lot of vacant
space on upper index pages (which must once have held downlinks to those
pages). Which means more upper pages traversed to get to the target
leaf page than we'd have in a non-bloated index. Without more
experimental evidence than we've got at hand, I'm disinclined to suppose
that index bloat is free.
> This extra bloat was one of the reasons the partial index was avoided in
> "Why does the query planner use two full indexes, when a dedicated partial
> index exists?"
Interesting point, but it's far from clear that the planner was wrong in
supposing that that bloat had significant cost. We agree that the
current 9.2 correction is too large, but it doesn't follow that zero is
a better value.
>> So from that standpoint,
>> the ln() form of the fudge factor seems quite reasonable as a crude form
>> of index descent cost estimate. The fact that we're needing to dial
>> it down so much reinforces my feeling that descent costs are close to
>> negligible in practice.
> If they are negligible, why do we really care that it use a partial index
> vs a full index?
TBH, in situations like the ones I'm thinking about it's not clear that
a partial index is a win at all. The cases where a partial index really
wins are where it doesn't index rows that you would otherwise have to
visit and make a non-indexed predicate test against --- and those costs
we definitely do model. However, if the planner doesn't pick the
partial index if available, people are going to report that as a bug.
They won't be able to find out that they're wasting their time defining
a partial index if the planner won't pick it.
So, between the bloat issue and the partial-index issue, I think it's
important that there be some component of indexscan cost that varies
according to index size, even when the same number of leaf pages and
leaf index entries will be visited. It does not have to be a large
component; all experience to date says that it shouldn't be very large.
But there needs to be something.
regards, tom lane
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 4.7 KB |
In response to
- Re: [PERFORM] Slow query: bitmap scan troubles at 2013-01-06 16:29:17 from Jeff Janes
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Simon Riggs | 2013-01-06 18:19:10 | Re: [PERFORM] Slow query: bitmap scan troubles |
| Previous Message | Jeff Janes | 2013-01-06 16:29:17 | Re: [PERFORM] Slow query: bitmap scan troubles |
Browse pgsql-performance by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Simon Riggs | 2013-01-06 18:19:10 | Re: [PERFORM] Slow query: bitmap scan troubles |
| Previous Message | Jeff Janes | 2013-01-06 16:29:17 | Re: [PERFORM] Slow query: bitmap scan troubles |